C++ 反汇编
配套资源下载
环境及工具
反汇编引擎工作原理(可略过)
基本数据类型的表现形式
程序的真正入口
各种表达式的求值过程
本文档使用 MrDoc 发布
-
+
首页
基本数据类型的表现形式
## 整数 - **int 类型与 long 类型都占 4 字节,short 类型占 2 字节,long long 类型占 8 字节。** - 由于二进制数不方便显示和阅读,因此内存中的数据采用十六进制数表示。 1 字节由 2 个十六进制数组成,在进制转换中,1 个十六进制数可用 4 个二进制数表示,每个二进制数表示 1 位,因此 **1 字节在内存中占 8 位**。 ### 无符号整数 - 取值范围为 0x00000000~0xFFFFFFFF,如果转换为十进制数,则表示范围为 **0~4294967295**。 - 当无符号整型不足 32 位时,用 0 来填充剩余高位,直到**占满 4 字节内存空间为止**。 - 在内存中以“**小尾方式**”存放。“小尾方式”存放以字节为单位,按照数据类型的长度,**低数据位放在内存的低端,高数据位放在内存的高端**,如 0x12345678,会存储为 78 56 34 12(这里的 78,是最低的个位和十位)。 - 无符号整数不存在正负之分,都是正数。 ### 有符号整数 - 有符号整数中用来表示符号的是最高位,即符号位。**最高位为 0 表示正数,最高位为 1 表示负数**。因此有符号整数的取值范围要比无符号整数取值范围少 1 位,即 0x80000000~0x7FFFFFFF,如果转换为十进制数,则表示范围为 -2 147 483 648~2 147 483 647。 - **负数在内存中都是以补码形式存放的,补码的规则是用 0 减去这个数的绝对值,也可以简单地表达为对这个数值按二进制位取反加 1。** - 为什么负数要用补码来存,因为为了实现 i+(-i)=0,正负数相加等于零的效果。 - 对于 4 字节补码,0x80000000 所表达的意义可以是负数 0,也可以是 0x80000001 减去 1。因为 0 的正负值是相等的,没有必要再用负数 0,所以就把这个值的意义规定为 0x80000001 减去 1,这样 **0x80000000 也就成为 4 字节负数的最小值了**。 - 查看用十六进制数表示时的最高位,最高位小于 8 则为正数,大于等于 8 则为负数。 - 在内存中判断是有符号还是无符号的办法:根据指令或者已知 API 的定义进行判断。比如 MessageBoxA,第四个参数是无符号整数。示例如下: ```c #include <iostream> int main() { __debugbreak(); int i = 1; int j = -1; int k = 123456789; return 0; } ``` 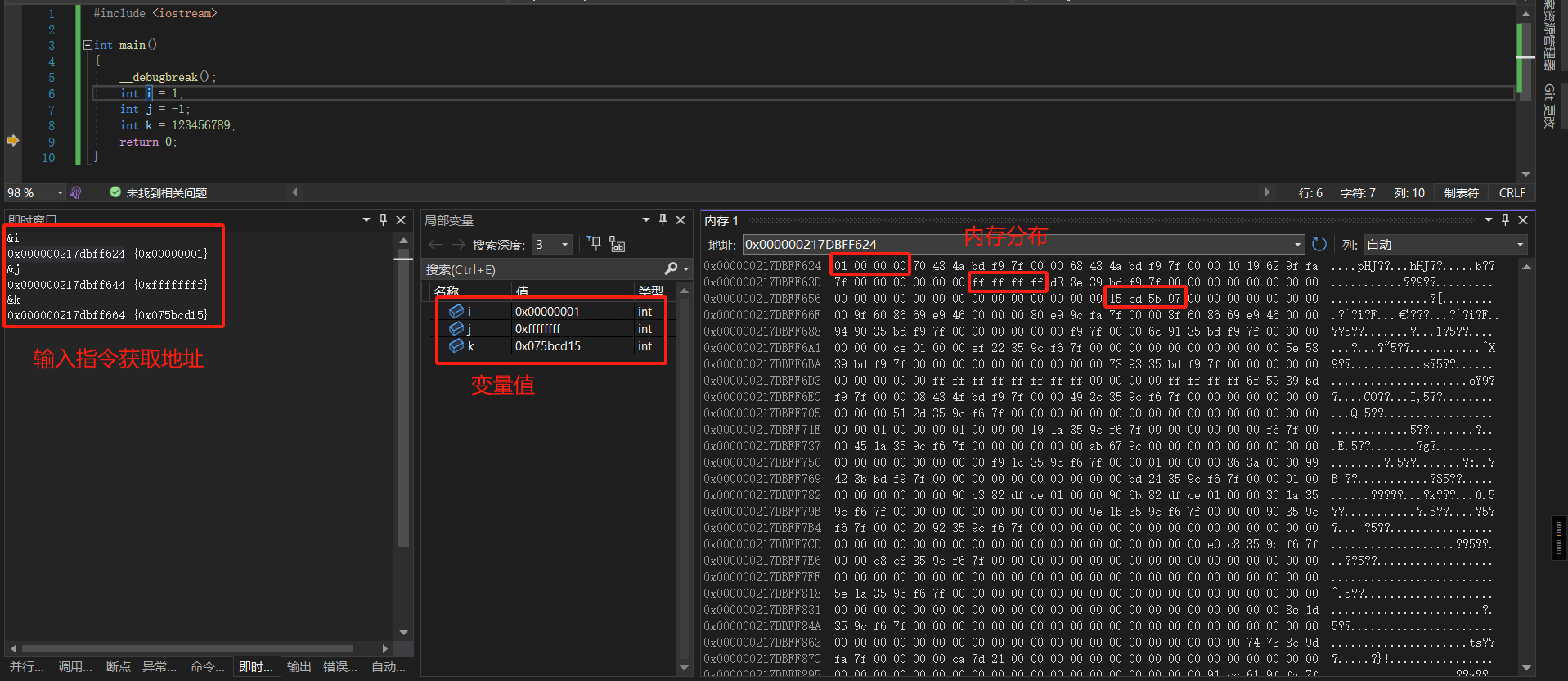 ## 浮点数 ### 定点实数的优缺点 - 可以约定两个高字节存放整数部分,两个低字节存储小数部分。好处是计算效率高,缺点也显而易见:存储不灵活,比如我们想存储 65536.5,由于整数的表达范围超过了 2 字节,就无法用定点实数存储方式了。 ### 浮点数的存储方式 - 浮点实数存储方式,道理很简单,就是**用一部分二进制位存放小数点的位置信息**,我们可以称之为“指数域”,**其他的数据位用来存储没有小数点时的数据和符号**,我们可以称之为“数据域”“符号域”。在访问时取得指数域,与数据域运算后得到真值,如 67.625,利用浮点实数存储方式,数据域可以记录为 67625,小数点的位置可以记为 10 的-3 次方,对该数进行访问时计算一下即可。 - float(单精度)、double(双精度)。**float 在内存中占 4 字节,double 在内存中占 8 字节。** - 浮点类型并不是将一个浮点小数直接转换成二进制数保存,而是将浮点小数转换成的二进制码重新编码,再进行存储。**C/C++的浮点数是有符号的。** - 在 C/C++中,将浮点数强制转换为整数时,**不会采用数学上四舍五入的方式,而是舍弃掉小数部分**(也就是“向零取整”),不会进位。 - 浮点数的操作不会用到通用寄存器,而是会**使用浮点协处理器的浮点寄存器,专门对浮点数进行运算处理。** #### float 类型的 IEEE 编码 - float类型在内存中占 4 字节(32 位)。最高位用于表示符号,在剩余的 31 位中,从左向右取 8 位表示指数,其余表示尾数。 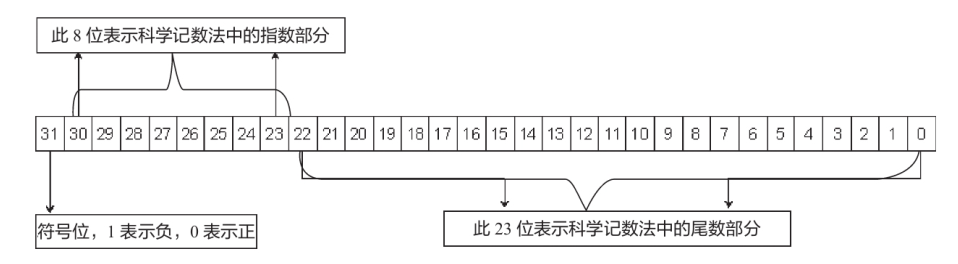 - **举例一定要看** - 举例:float 类型的 12.25f 转换为 IEEE 编码,须将 12.25f 转换成对应的二进制数 1100.01,整数部分为 1100,小数部分为 01(小数部分的 1 表示 2^-1 也就是 0.5,01 表示 2^-2 也就是 0.25);小数点向左移动,每移动 1 次,指数加 1,移动到**除符号位的最高位为 1 处**,停止移动,这里**移动 3 次**。对 12.25f 进行科学记数法转换后二进制部分为1.10001,指数部分为 3。**在 IEEE 编码中,由于在二进制情况下,最高位始终为 1(二进制科学计数法肯定最高位是 1),为一个恒定值,故将其**`忽略不计`。这里是一个正数,所以**符号位添加 0**。 - 转换过程如下: - 符号位:0。 - 指数位:十进制 3+127=130,转换为二进制为 10000010。 - 尾数位:10001 000000000000000000(**当不足 23 位时,低位补 0 填充,最高位的 1 默认去掉)**。 - 为什么**指数位要加 127**呢?这是因为**指数可能出现负数**,十进制数 127 可表示为二进制数 01111111,IEEE 编码方式规定,当指数小于 0111111 时为一个负数,反之为正数,因此 01111111 为 0。 - 此时 12.25f 转换成二进制是 **0 10000010 10001000000000000000000(对比上面结果认真思考下这个数字的由来),尾数部分最高位肯定是1所以删掉了**。转换成十六进制是 0x41440000,内存中以小尾方式进行排列,故为 00 00 44 41。 - 举例 2: - -0.125f 经转换后二进制部分为 0.001,用科学记数法表示为 1.0,指数为-3。 - -0.125f IEEE转换后各位的情况如下。 - 符号位:1。 - 指数位:十进制127+(-3),转换为二进制是 01111100,如果不足 8 位,则高位补 0。 - 尾数位:00000000000000000000000。 - -0.125f 转换后的 IEEE 编码二进制拼接为 10111110000000000000000000000000。转换成十六进制数为 0xBE000000,内存中显示为 00 00 00 BE。 - 举例 3: - 1.3f 转换后的 IEEE 编码二进制拼接为 00111111101001100110011001100110。转换成十六进制数为 0x3FA66666,在内存中显示为 66 66 A6 3F。由于在转换二进制过程中产生了无穷值,舍弃了部分位数,所以进行 IEEE 编码转换后得到的是一个近似值,存在一定的误差。再次将这个 IEEE 编码值转换成十进制小数,得到的值为 1.2516582,四舍五入保留一位小数之后为 1.3。**这就解释了为什么 C++ 在比较浮点数值是否为 0 时(C/C++比较浮点数不能使用==),要做一个区间比较而不是直接进行等值比较。** 示例如下: ```c #include <iostream> int main() { float i = 12.25; float j = -0.125; float k = 1.3; __debugbreak(); return 0; } ``` 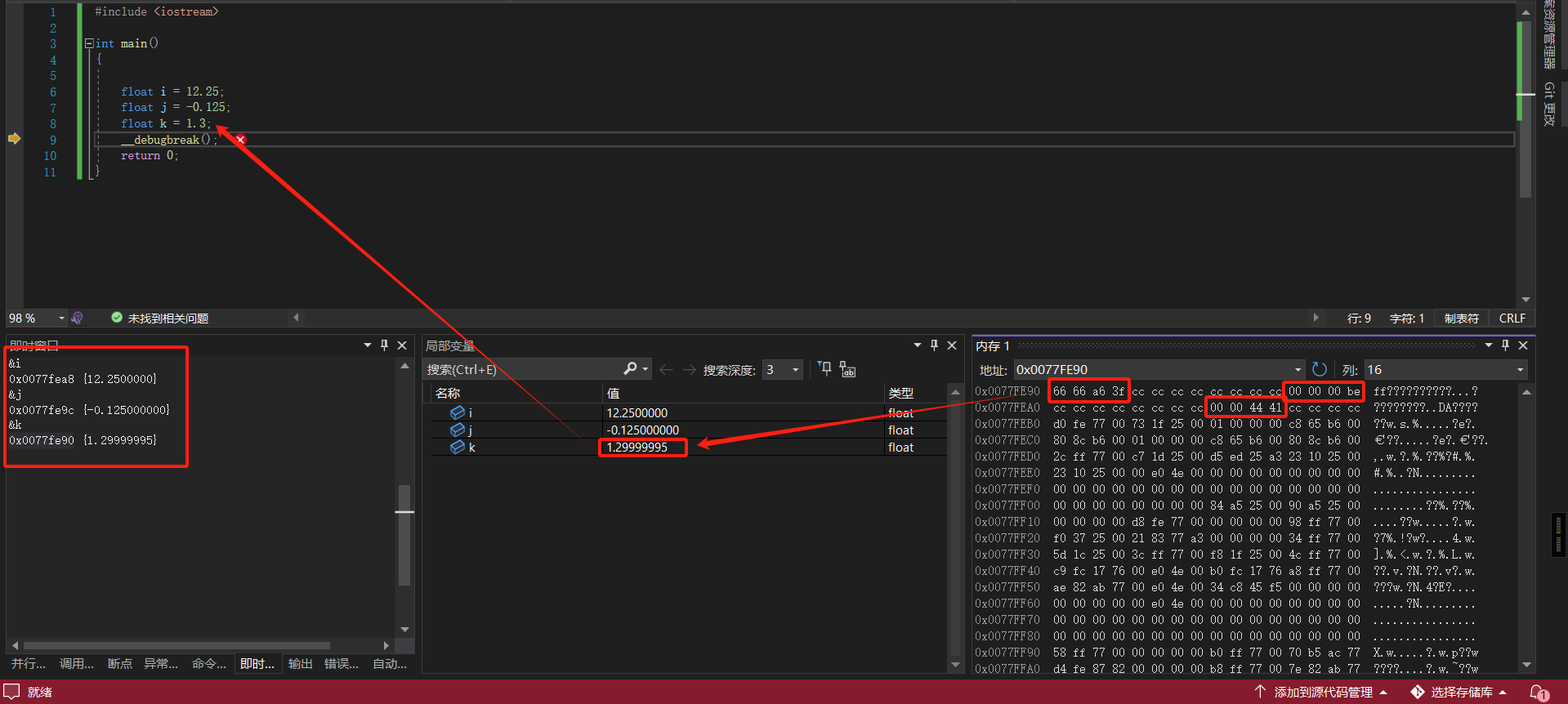 - 浮点数的正确比较方式 ```c float f1 = 0.0001f; // 精确范围 if (f2 >= -f1 && f2 <= f1) { // f2等于0,这应该是书本的一个错误。 } ``` #### double 的存储方式 - double 和 float 大同小异,double 类型占 8 字节的内存空间,同样,最高位也用于表示符号,**指数位占 11 位,剩余 52 位表示位数。** - 由于扩大了精度,因此指数范围使用 11 位正数表示,**加 1023 后可用于指数符号判断**。 - 示例代码一样,内存中的数据如下: 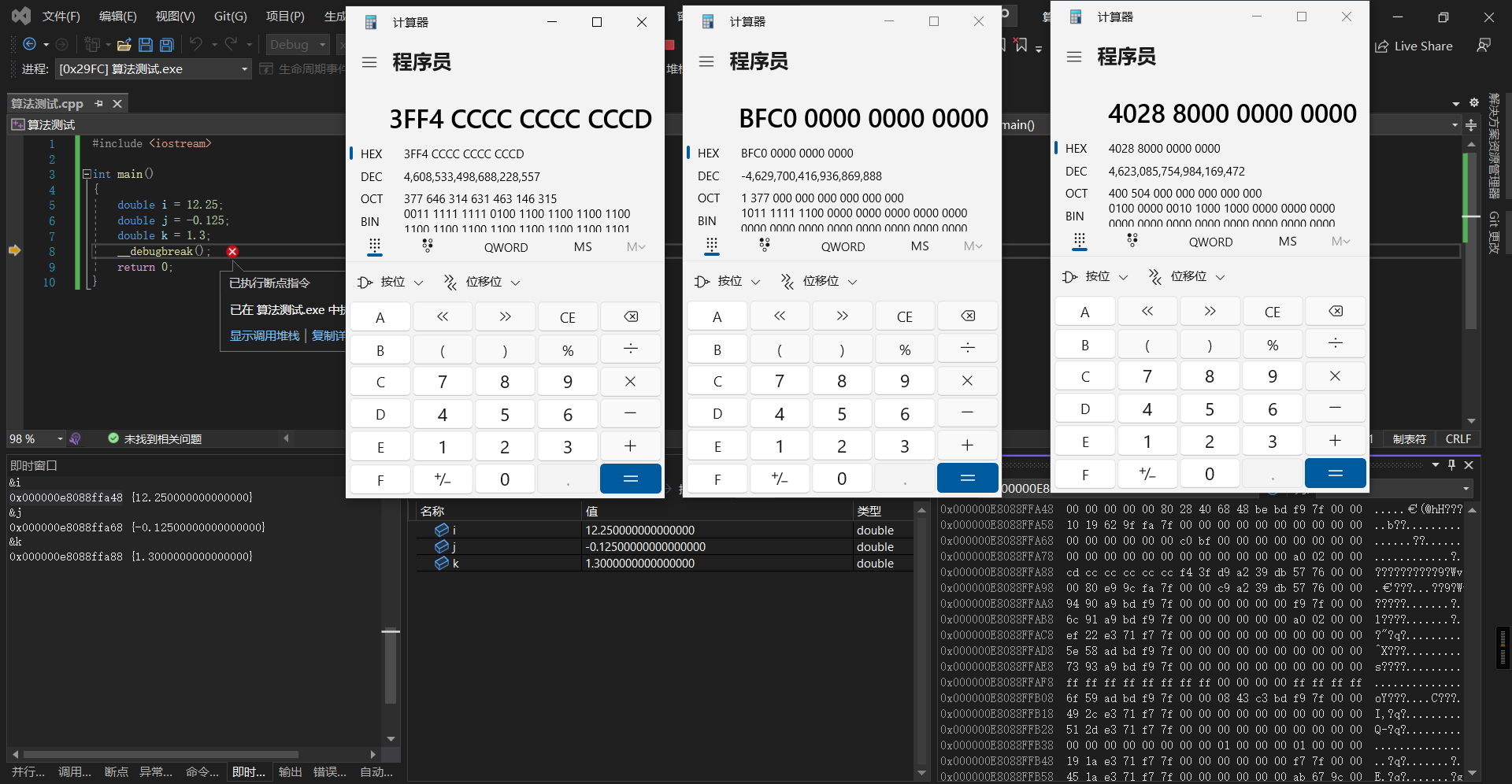 ### 基本浮点数指令(看看就好,遇到了搜下就行) - 浮点数操作是通过浮点寄存器实现的,而普通数据类型使用的是通用寄存器,它们分别**使用两套不同的指令。** - 在`早期 CPU `中,浮点寄存器是通过栈结构实现的,由 ST(0)~ ST(7)共 8 个栈空间组成,每个浮点寄存器占8字节。**每次使用浮点寄存器都是率先使用ST(0),而不能越过 ST(0)直接使用 ST(1)**。浮点寄存器的使用就是压栈、出栈的过程。当 ST(0)中存在数据时,**执行压栈操作后,ST(0)中的数据将装入 ST(1)中,如无出栈操作,将按顺序向下压栈,直到将浮点寄存器占满为止**。常用浮点数指令的介绍如表所示,其中,IN 表示操作数入栈,OUT 表示操作数出栈。 | 指令名称 | 使用格式 | 指令功能 | | :---: | :---: | :---: | | FLD | FLD IN | 将浮点数 IN 压入 ST(0)中。IN(mem 32/64/80) | | FILD | FILD IN | 将整数 IN 压入 ST(0)中。IN(mem 32/64/80) | | FLDZ | FLDZ | 将 0.0 压入 ST(0)中 | | FLD1 | FLD1(不知道是 1 还是 l) | 将 1.0 压入 ST(0)中 | | FST | FST OUT | ST(0) 中的数据以浮点形式存入 OUT 地址中。OUT(mem 32/64)会根据操作数的位数进行不同精度的转换 | | FSTP | FSTP OUT | 和 FST 指令一样,但会执行一次出栈操作 | | FIST | FIST OUT | ST(0) 中的数据以整数形式存入 OUT 地址中。OUT(mem 32/64) | | FISTP | FISTP OUT | 和 FIST 指令一样,但会执行一次出栈操作 | | FCOM | FCOM IN | 将 IN 地址数据与 ST(0)进行史书比较,影响对应标记位 | | FTST | FTST | 比较 ST(0)是否为 0.0,影响对应标记位 | | FADD | FADD IN | 将 IN 地址内的数据与 ST(0)做加法运算,结果放入 ST(0)中 | | FADDP | FADDP ST(N),ST | 将 ST(N)中的数据与 ST(0)中的数据做加法运算,N 为 0~7 中的任意一个数,先执行一次出栈操作,然后将相加结果放入 ST(0)中保存 | - **其他运算指令和普通指令类似,只须在前面加 F 即可,如 FSUB 和 FSUBP 等。** - 在使用浮点指令时,都要先利用 ST(0)进行运算。当 ST(0)中有值时,便会将 ST(0)中的数据顺序向下存放到 ST(1)中,然后再将数据放入 ST(0)。如果再次操作 ST(0),则会先将 ST(1)中的数据放入 ST(2),然后将 ST(0)中的数据放入 ST(1),最后将新的数据存放到 ST(0)。以此类推,在 8 个浮点寄存器都有值的情况下继续向 ST(0)中的存放数据,这时会丢弃 ST(7)中的数据信息。 - 1997 年开始,Intel 和 AMD 都引入了**媒体指令(MMX)**,这些指令**允许多个操作并行,允许对多个不同的数据并行执行同一操作**。近年来,这些扩展有了长足的发展。名字经过了一系列的修改,从 MMX 到 **SSE(流 SIMD 扩展)**,以及最新的 **AVX(高级向量扩展)**。每一代都有一些不同的版本。每个扩展都用来管理寄存器中的数据,这些寄存器在 MMX 中被称为 **MM 寄存器**,在 SSE 中被称为 **XMM 寄存器**,在 AVX 中被称为 **YMM 寄存器**。**MM 寄存器是 64 位的,XMM 是 128 位的,而 YMM 是 256 位的。**每个 YMM 寄存器可以存放 8 个 32 位值或 4 个 64 位值,可以是整数,也可以是浮点数。**YMM 寄存器一共有 16 个(YMM0~YMM15),而 XMM 是 YMM 的低 128 位**。常用 SSE 浮点数指令的介绍如表所示。**(简单来说就是寄存器的扩展)** | 指令名称 | 使用格式 | 指令功能 | | :-----: | :-----: | :-----: | | MOVSS | xmm1,xmm2<br>xmm2,mem32<br>xmm2/mem32,xmm1 | 传送单精度数 | | MOVSD | xmm1,xmm2<br>xmm2,mem64<br>xmm2/mem64,xmm1 | 传送双精度数 | | MOVAPS | xmm1,xmm2/mem128<br>xmm1/mem128,xmm2 | 传送对齐的封装好的单精度数 | | MOVAPD | xmm1,xmm2/mem128<br>xmm1/mem128,xmm2 | 传送对齐的封装好的双精度数 | | ADDSS | xmm1,xmm2/mem32 | 单精度加法 | | ADDSD | xmm1,xmm2/mem64 | 双精度加法 | | ADDPS | xmm1,xmm2/mem128 | 并行 4 个单精度加法 | | ADDPD | xmm1,xmm2/mem128 | 并行 2 个双精度加法 | | SUBSS | xmm1,xmm2/mem32 | 单精度数减法 | | SUBSD | xmm1,xmm2/mem64 | 双精度数减法 | | SUBPS | xmm1,xmm2/mem128 | 并行 4 个单精度数减法 | | SUBPD | xmm1,xmm2/mem128 | 并行 2 个双精度减法 | | MULSS | xmm1,xmm2/mem32 | 单精度数乘法 | | MULSD | xmm1,xmm2/mem64 | 双精度数乘法 | | MULPS | xmm1,xmm2/mem128 | 并行 4 个单精度数乘法 | | MULPD | xmm1,xmm2/mem128 | 并行 2 个双精度数乘法 | | DIVSS | xmm1,xmm2/mem32 | 单精度数除法 | | DIBSD | xmm1,xmm2/mem64 | 双精度数除法 | | DIVPS | xmm1,xmm2/mem128 | 并行 4 个单精度数除法 | | DIVPD | xmm1,xmm2/mem128 | 并行 2 个双精度数除法 | | CVTTSS2SI | reg32,xmm1/mem32<br>reg64,xmm1/mem64 | 用截断的方法将单精度数转换为整数 | | CVTTSD2SI | reg32,xmm1/mem32<br>reg64,xmm1/mem64 | 用截断的方法将双精度数转换为整数 | | CVTSI2SS | xmm1,reg32/mem32<br>xmm1,reg64/mem64 | 将整数转换为单精度数 | | CVTSI2SD | xmm1,reg32/mem32<br>xmm1,reg64/mem64 | 将整数转换为双精度数 | ```c #include <stdio.h> int main(int argc, char* argv[]) { float f = (float)argc; printf("%f", f); argc = (int)f; printf("%d", argc); return 0; } ``` ```asm ; x86 vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_C= qword ptr -0Ch var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ecx cvtsi2ss xmm0, [ebp+argc] ; 将整数转为单精度数 movss [ebp+var_4], xmm0 ; 传送单精度数 cvtss2sd xmm0, [ebp+var_4] ; 将整数转为双精度数字,从dword 4字节变成qword 8字节。 sub esp, 8 movsd [esp+0Ch+var_C], xmm0 ; 传送双精度数 push offset unk_412160 ; 压入 %f call sub_401090 ; 调用 printf add esp, 0Ch ; 栈平衡 cvttss2si eax, [ebp+var_4] ; 用截断的方法将单精度数转换为整数 mov [ebp+argc], eax mov ecx, [ebp+argc] push ecx push offset unk_412164 ; offset 运算符是返回数据标号的偏移量 call sub_401090 ; 调用 printf add esp, 8 xor eax, eax mov esp, ebp pop ebp retn _main endp ``` ```asm ; x86 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h ; 栈对齐,如果没有对齐,CPU可能需要两次内存访问才能获取栈内数据。栈顶指针必须是16字节的整数倍。 sub esp, 30h call ___main fild [ebp+argc] ; 从内存读取整数,转换为80 位扩展双精度浮点数(long double),并压入 x87 浮点寄存器栈(ST(0))。 fstp dword ptr [esp+2Ch] ; 将栈顶 ST(0) 的值存储到内存或另一个 FPU 寄存器。注意这里的dword和下面的qword会自动转换为对应的精度。 fld dword ptr [esp+2Ch] ; 将浮点数压入 FPU 寄存器栈(ST(0))。它可以从内存或另一个 FPU 寄存器加载数据。 fstp qword ptr [esp+4] ; 和上面一行看似多此一举的指令就是为了将 argc的值赋值给 [esp+4] 。 mov dword ptr [esp], offset Format ; "%f" call _printf fld dword ptr [esp+2Ch] fnstcw word ptr [esp+1Eh] ; 用于从内存加载 FPU 控制字(Control Word),从而立即生效改变浮点运算的行为(如舍入模式、异常屏蔽等)。影响后续所有浮点运算(如舍入方式、异常处理)。 movzx eax, word ptr [esp+1Eh] ; 用于将较小位宽的数据高位零扩展(Zero-Extend)到较大位宽,并存储到目标寄存器。它常用于无符号数转换,避免符号位污染。 or ah, 0Ch mov [esp+1Ch], ax fldcw word ptr [esp+1Ch] ; fistp [ebp+argc] ; x87 FPU 浮点转整数存储并出栈 fldcw word ptr [esp+1Eh] mov eax, [ebp+argc] mov [esp+4], eax mov dword ptr [esp], offset aD ; "%d" call _printf mov eax, 0 leave retn _main endp ``` - x87 FPU(浮点处理单元)采用了一种独特的寄存器栈(Register Stack)设计,它兼具寄存器组和栈(LIFO)的特性: - 物理结构:8 个独立的 80 位寄存器; - 逻辑行为:栈结构(LIFO) - TOP 是 3 位字段(位于 FPU 状态字中),指向当前栈顶 ST(0)。 - 压栈(如 fld):TOP 减 1,新值存入新的 ST(0)。 - 出栈(如 fstp):TOP 加 1,原 ST(0) 逻辑上被移除。 ```asm ; x86 clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_24= dword ptr -24h var_20= qword ptr -20h var_18= dword ptr -18h var_14= dword ptr -14h var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 24h mov eax, [ebp+argv] mov ecx, [ebp+argc] mov [ebp+var_4], 0 mov edx, [ebp+argc] cvtsi2ss xmm0, edx ; 将整数转为单精度数 movss [ebp+var_8], xmm0 ; 传送单精度数 movss xmm0, [ebp+var_8] cvtss2sd xmm0, xmm0 ; 将整数转为双精度数字,从dword 4字节变成qword 8字节。 lea edx, unk_412160 mov [esp+24h+var_24], edx movsd [esp+24h+var_20], xmm0 ; 传送双精度数 mov [ebp+var_C], eax mov [ebp+var_10], ecx call sub_401070 cvttss2si ecx, [ebp+var_8] ; 用截断的方法将单精度数转换为整数 mov [ebp+argc], ecx mov ecx, [ebp+argc] lea edx, unk_412163 mov [esp+24h+var_24], edx mov dword ptr [esp+24h+var_20], ecx mov [ebp+var_14], eax call sub_401070 xor ecx, ecx mov [ebp+var_18], eax mov eax, ecx add esp, 24h pop ebp retn _main endp ``` ```asm ; x64 vs ; int __cdecl main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx mov [rsp+arg_0], ecx sub rsp, 38h cvtsi2ss xmm0, [rsp+38h+arg_0] ; 将整数转换为单精度数 movss [rsp+38h+var_18], xmm0 ; 传送单精度数 cvtss2sd xmm0, [rsp+38h+var_18] ; 将源操作数(第二个操作数)中的单精度浮点数值转换为双精度浮点数值,并将结果与目标操作数(第一个操作数)的高64位合并存储。 movaps xmm1, xmm0 ; 在内存和 XMM 寄存器之间,或者两个 XMM 寄存器之间移动对齐的打包单精度浮点数据(128 位)。处理的是128位数据包,但里面装的是4个单精度浮点数 movq rdx, xmm1 ; x86 指令集中用来搬运 64 位数据的指令 lea rcx, Format ; "%f" call printf cvttss2si eax, [rsp+38h+var_18] ; 用截断的方法将单精度数转换为整数 mov [rsp+38h+arg_0], eax mov edx, [rsp+38h+arg_0] lea rcx, aD ; "%d" call printf xor eax, eax add rsp, 38h retn main endp ``` ```asm ; x64 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public main main proc near var_4= dword ptr -4 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 30h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main cvtsi2ss xmm0, [rbp+arg_0] movss [rbp+var_4], xmm0 cvtss2sd xmm0, [rbp+var_4] movq rax, xmm0 mov rdx, rax movq xmm1, rdx mov rdx, rax lea rcx, Format ; "%f" call printf movss xmm0, [rbp+var_4] cvttss2si eax, xmm0 mov [rbp+arg_0], eax mov edx, [rbp+arg_0] lea rcx, aD ; "%d" call printf mov eax, 0 add rsp, 30h pop rbp retn main endp ``` ```asm ; x64 clang ; int __cdecl main(int argc, const char **argv, const char **envp) main proc near var_20= dword ptr -20h var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 48h mov [rsp+48h+var_4], 0 mov [rsp+48h+var_10], rdx mov [rsp+48h+var_14], ecx mov ecx, [rsp+48h+var_14] cvtsi2ss xmm0, ecx movss [rsp+48h+var_18], xmm0 movss xmm0, [rsp+48h+var_18] cvtss2sd xmm0, xmm0 lea rcx, unk_1400122C0 movaps xmm1, xmm0 movq rdx, xmm0 call sub_140001070 cvttss2si r8d, [rsp+48h+var_18] mov [rsp+48h+var_14], r8d mov edx, [rsp+48h+var_14] lea rcx, unk_1400122C3 mov [rsp+48h+var_1C], eax call sub_140001070 xor edx, edx mov [rsp+48h+var_20], eax mov eax, edx add rsp, 48h retn main endp ``` - 在 64 位的环境下,三个编译器编译的代码反而没有很大区别。 - 从示例中可以发现,float 类型的浮点数虽然占 4 字节,但是**使用浮点栈将以 8 字节方式进行处理,而使用媒体寄存器则以 4 字节处理**。当浮点数作为参数时,并不能直接压栈,PUSH指令只能传入 4 字节数据到栈中,这样会丢失 4 字节数据。这就是使用 printf 函数以整数方式输出浮点数时会产生错误的原因。printf以整数方式输出时,将对应参数作为4字节数据长度,按补码方式解释,而真正压入的参数为浮点类型时,却是8字节长度,需要按浮点编码方式解释。**浮点数作为返回值的情况也是如此,在 32 位程序中使用浮点栈 st(0)作为返回值同样需要传递 8 字节数据,64 位程序中使用媒体寄存器 xmm0 作为返回值只需要传递 4 字节**。示例如下: ```c #include <stdio.h> float getFloat() { return 12.25f; } int main(int argc, char* argv[]) { float f = getFloat(); return 0; } ``` ```asm ; x86 vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ecx call sub_401000 fstp [ebp+var_4] ; 将栈顶 ST(0) 的值存储到内存或另一个 FPU 寄存器。 xor eax, eax mov esp, ebp pop ebp retn _main endp sub_401000 proc near push ebp mov ebp, esp fld ds:flt_40D150 ; 将返回值入栈到st(0)中,单精度数转换为双精度数入栈 pop ebp retn sub_401000 endp ``` ```asm ; x86 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h ; 栈对齐 sub esp, 10h call ___main ; 调用初始化函数 call __Z8getFloatv ; getFloat(void) fstp dword ptr [esp+0Ch] ; st(0)双精度转为单精度并出栈。 mov eax, 0 leave retn _main endp ; _DWORD getFloat(void) public __Z8getFloatv __Z8getFloatv proc near fld ds:flt_404000 ; 返回值放到 st(0)中并转为双精度。 retn __Z8getFloatv endp ``` - 和 x86 vs 一样 ```asm ; x86 clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_14= dword ptr -14h var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 14h mov eax, [ebp+argv] mov ecx, [ebp+argc] mov [ebp+var_4], 0 mov [ebp+var_10], eax mov [ebp+var_14], ecx call sub_401000 fstp [ebp+var_C] movss xmm0, [ebp+var_C] xor eax, eax movss [ebp+var_8], xmm0 add esp, 14h pop ebp retn _main endp sub_401000 proc near push ebp mov ebp, esp fld ds:flt_40D150 pop ebp retn sub_401000 endp ``` - 除了结果多进行了一次复制之外,和前面差不多。 ```asm ; x64 vs ; int __cdecl main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx mov [rsp+arg_0], ecx sub rsp, 38h call sub_140001000 movss [rsp+38h+var_18], xmm0 ; 从 xmm0 获取结果 xor eax, eax add rsp, 38h retn main endp sub_140001000 proc near movss xmm0, cs:dword_14000D2C0 retn sub_140001000 endp ``` - 不在通过 fstp(出栈) 和 fld(压栈) 来移动,而是通过 movss(传送单精度数) 来移动 ```asm ; x64 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public main main proc near var_4= dword ptr -4 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 30h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main call _Z8getFloatv ; getFloat(void) movd eax, xmm0 mov [rbp+var_4], eax mov eax, 0 add rsp, 30h pop rbp retn main endp ; __int64 getFloat(void) public _Z8getFloatv _Z8getFloatv proc near movss xmm0, cs:dword_404000 retn _Z8getFloatv endp ``` - movd:Move Doubleword(移动双字),主要用于在通用寄存器(如 EAX、EBX)和SIMD 寄存器(如 XMM、MMX)之间传输 32 位(4 字节)数据。 ```asm ; x64 clang ; int __cdecl main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 38h mov [rsp+38h+var_4], 0 mov [rsp+38h+var_10], rdx mov [rsp+38h+var_14], ecx call sub_140001000 xor eax, eax movss [rsp+38h+var_18], xmm0 add rsp, 38h retn main endp sub_140001000 proc near movss xmm0, cs:dword_14000D2C0 retn sub_140001000 endp ``` - 具体为什么要这么做,问了下 AI,结果如下: 1. 浮点栈(x87 FPU)的 8 字节处理 - 历史原因 - 早期 x87 浮点协处理器(FPU)的寄存器栈设计为 80 位扩展精度(10 字节),但实际运算时会默认将 32 位 `float` 扩展为 64 位 `double`(8 字节)处理。主要原因包括: - **统一运算逻辑**:x87 FPU 对所有浮点类型(`float`/`double`/`extended`)使用同一套寄存器,避免频繁切换精度模式。 - **精度保障**:64 位处理能减少中间计算的舍入误差。 - 栈对齐要求 - 在 x86-32 架构中,栈通常按机器字长(4 字节)或更大(如 8 字节)对齐,64 位处理更符合对齐优化,提升性能。 2. 媒体寄存器(SSE/AVX)的 4 字节处理 - SIMD 优化 - SSE/AVX 等媒体寄存器直接支持 32 位 `float` 的并行操作(如 `movss`、`addps` 指令),无需扩展精度: - **寄存器宽度更大**:例如 128 位 XMM 寄存器可同时处理 4 个 `float`(4×32 位),效率更高。 - **现代编译器默认行为**:优先使用 SSE 指令(而非 x87)处理浮点运算,避免精度转换开销。 - 内存对齐 - SSE 要求 32 位 `float` 内存按 4 字节对齐,直接加载/存储即可,无需填充或扩展。 3. 关键区别总结 |**特性**|**x87 FPU(浮点栈)**|**SSE/AVX(媒体寄存器)**| |---|---|---| |**处理方式**|32位`float`扩展为64位处理|原生32位处理| |**寄存器设计**|80位扩展精度(实际用64位)|128/256位支持并行32位操作| |**对齐要求**|兼容8字节栈对齐|严格4字节内存对齐| |**现代应用**|逐渐淘汰(性能低、精度复杂)|主流(高效、结果确定)| - 书上虽然已经把反汇编代码贴出来了,但是还是建议实际动手操作一遍。 ## 字符和字符串 - **在 C++中,以'\0'作为字符串结束标记**。每个字符都记录在一张表中,它们各自对应一个唯一编号,系统通过这些编号查找到对应的字符并显示。 ### 字符的编码 - 在C++中,字符的编码格式分为两种:**ASCII 和 Unicode**。 - ASCII 编码在内存中**占 1 字节**,由 0~255 之间的数字组成。 - Unicode **占双字节**、表示范围为 0~65535。 - **char** 定义 ASCII 编码格式的字符,使用 **wchar_t** 定义 Unicode 编码格式的字符。**wchar_t 中保存 ASCII 编码,不足位补 0**,如字符'a'的 ASCII 编码为 0x61,Unicode 编码为 0x0061。 - **ASCII 编码与 Unicode 编码都可以用来存储汉字**,但是它们对汉字的编码方式各不相同。 - ASCII 使用 **GB2312-80**,又名汉字国标码,保存了 6763 个常用汉字编码,用两个字节表示一个汉字。在 GB2312-80 中用区和位来定位,第一个字节保存每个区,共 94 个区;第二个字节保存每个区中的位,共 94 位。详细信息可查看 GB2312-80 编码的说明。 - **Unicode 使用 UCS-2 编码格式,最多可存储 65536 个字符**。汉字博大精深,其中有简体字、繁体字,还有网络中流行的火星文,它们的总和远远超过了 UCS-2 的存储范围,所以 UCS-2 编码格式中只保存了常用字。为了将所有的汉字都容纳进来,Unicode 也采用了与 ASCII 类似的方式——**用两个 Unicode 编码(4字节)解释一个汉字,一般称之为 UCS-4 编码格式**。UCS-2 编码表的使用和 ASCII 编码表的使用是一样的,每个数字编号在表中对应一个汉字,从 0x4E00 到 0x9520 为汉字编码区。例如,在 UCS-2 中,**“烫”字的编码为 0x70EB**。详细信息可以查看随书附录 [【附件】汉字UCS-2编码表.zip](/media/attachment/2025/07/%E6%B1%89%E5%AD%97UCS-2%E7%BC%96%E7%A0%81%E8%A1%A8.zip)。 ### 字符串的存储方式 - 字符串的保存方式有如下两种: 1. **在首地址的 4 字节中保存字符串的总长度**。 - 优点:**获取字符串长度时,不用遍历字符串中的每个字符**,取得首地址的前 n 字节就可以得到字符串的长度(n 的取值一般是 1、2、4)。 - 缺点:字符串长度**不能超过** n 字节的表示范围,且要多**开销** n 字节空间保存长度。如果涉及通信,双方交互前必须事先知道通信字符串的长度。 2. **在字符串的结尾处使用一个规定好的特殊字符,即结束符**。 - 优点:**没有记录长度的开销**,即不需要存储空间记录长度信息;另外,如果涉及通信,通信字符串可以根据实际情况随时结束,结束时附上结束符即可。 - 缺点:**获取字符串长度需要遍历所有字符**,寻找特殊结尾字符,在某些情况下处理效率低。 - C++使用结束符'\0'作为字符串结束标志。**ASCII 编码使用一个字节'\0',Unicode 编码使用两个字节'\0'**。 - 在程序中,一般都会使用一个变量来**存放字符串中第一个字符的地址**,以便于查找使用字符串。 - IDA 中,如果字符串未识别出来,**使用快捷键 A,便可将分析地址到'\0'解释为字符串。** ## 布尔类型 - **C++中定义 0 为假,非 0 为真。使用 bool 定义布尔类型变量。布尔类型在内存中占 1 字节。** ## 地址、指针和引用 - 在 C++ 中,地址标号使用十六进制表示,取一个变量的地址使用“&”符号,**只有变量才存在内存地址,常量没有地址(不包括 const 定义的伪常量,const 常量是编译器检查是否被修改,内存中还是变量)。** - 指针的定义使用“TYPE*”格式,TYPE 为数据类型,任何数据类型都可以定义指针。指针本身也是一种数据类型,用于保存各种数据类型在内存中的地址。指针变量同样可以取出地址,所以会出现多级指针。 - 引用的定义格式为“TYPE&”,TYPE 为数据类型。在 C++中是不可以单独定义的,并且在定义时就要进行初始化。引用表示一个变量的别名,对它的任何操作本质上都是在操作它所表示的变量。 ### 指针和地址的区别 - **在 32 位应用程序中,地址是一个由 32 位二进制数字组成的值;在 64 位应用程序中,地址是一个由 64 位二进制数字组成的值。** 由于指针保存的数据都是地址,所以**无论什么类型的指针,32 位程序都占据 4 字节的内存空间,64 位程序都占据 8 字节的内存空间**。 - 举例:如果是在一个int类型的指针中保存这个地址(假设为 0x0135FE04),就可以将其看作 int 类型数据的起始地址,向后数 4 字节到 0x0135FE08 处,将 0x0135FE04~0x0135FE08 中的数据按整型存储方式解释。 - 指针与地址的不同点 | 指针 | 地址 | | :----: | :----: | | 变量,保存变量地址 | 常量,内存标号 | | 可修改,再次保存其它变量地址 | 不可修改 | | 可以对其执行取地址操作 | 不可执行取地址操作 | | 包含对保存地址的解释信息 | 仅有地址值无法解释数据 | - 指针与地址的相同点 | 指针 | 地址 | | :----: | :----: | | 取出指向地址内存的数据 | 取出地址对应内存的数据 | | 对地址偏移后,取出数据 | 偏移后去数据,自身不变 | | 求两个地址值的差 | 求两个地址的差 | ### 指针的工作方式 - 指针保存的都是地址,为什么还需要类型作为修饰呢?因为我们需要用类型去解释这个地址中的数据。每种数据类型所占的内存空间不同,**指针只保存了存放数据的首地址,而没有指明该在哪里结束。这时就需要根据对应的类型来寻找解释数据的结束地址**。示例如下 ```c #include <stdio.h> int main(int argc, char* argv[]) { int n = 0x12345678; int *p1 = &n; char *p2 = (char*)&n; short *p3 = (short*)&n; printf("%08x \r\n", *p1); printf("%08x \r\n", *p2); printf("%08x \r\n", *p3); return 0; } /* 输出结果: 12345678 00000078 00005678 */ ``` ```asm ; x86 vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 10h mov [ebp+var_4], 12345678h ; n = 0x12345678 lea eax, [ebp+var_4] ; p1 = &n mov [ebp+var_8], eax ; ebp+var_8 中存储的是 12345678h 的地址 lea ecx, [ebp+var_4] ; p2 = &n mov [ebp+var_C], ecx ; 同 ebp+var_8 lea edx, [ebp+var_4] ; p3 = &n mov [ebp+var_10], edx ; 同 ebp+var_8 mov eax, [ebp+var_8] ; 将 ebp+var_8 中存储的值给 eax,eax则保存的是12345678h的地址 mov ecx, [eax] ; 从 eax 中将 12345678h 值取出来。 push ecx push offset a08x ; "%08x \r\n" call sub_4010A0 ; 调用 printf add esp, 8 ; 平衡栈 mov edx, [ebp+var_C] movsx eax, byte ptr [edx] ; 这里的 byte ptr 只取出了 1 个字节,带符号扩展传送指令 符号扩展的意思是,当计算机存储某一个有符号数时,符号位位于该数的第一位,所以,当扩展一个负数的时候需要将扩展的高位全赋为1.对于正数而言,符号扩展和零扩展MOVZX(无符号扩展传送)是一样的,将扩展的高位全赋为0。所以结果是 78。 push eax push offset a08x_0 ; "%08x \r\n" call sub_4010A0 add esp, 8 mov ecx, [ebp+var_10] movsx edx, word ptr [ecx] ; 这里的 word 只取出了 2 个字节,所以结果是 5678。 push edx push offset a08x_1 ; "%08x \r\n" call sub_4010A0 add esp, 8 xor eax, eax mov esp, ebp pop ebp retn _main endp ``` ```asm ; x86 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 20h call ___main ; 调用初始化 mov dword ptr [esp+10h], 12345678h lea eax, [esp+10h] mov [esp+1Ch], eax lea eax, [esp+10h] mov [esp+18h], eax lea eax, [esp+10h] mov [esp+14h], eax mov eax, [esp+1Ch] mov eax, [eax] mov [esp+4], eax mov dword ptr [esp], offset Format ; "%08x \r\n" call _printf mov eax, [esp+18h] movzx eax, byte ptr [eax] ; 取 1 字节内容 movsx eax, al ; 高位扩展到 4 字节,效率低了,可以直接 movsx eax, byte ptr [eax] mov [esp+4], eax mov dword ptr [esp], offset Format ; "%08x \r\n" call _printf mov eax, [esp+14h] movzx eax, word ptr [eax] cwde ; 效率低了,和上面同理 ;CBW(Convert Byte to Word): 将 AL 有符号扩展为 AX ;CWDE(Convert Word to Extended Double): 将 AX 有符号扩展为 EAX ;CDQ(Convert Doubleword to Quadword): 将 EAX 有符号扩展为 64 位数 EDX:EAX ;CWD(Convert Word to Doubleword): 将 AX 有符号扩展为 DX:AX mov [esp+4], eax mov dword ptr [esp], offset Format ; "%08x \r\n" call _printf mov eax, 0 leave retn _main endp ``` ```asm ; x86 clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_34= dword ptr -34h var_30= dword ptr -30h var_2C= dword ptr -2Ch var_28= dword ptr -28h var_24= dword ptr -24h var_20= dword ptr -20h var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push esi sub esp, 30h mov eax, [ebp+argv] mov ecx, [ebp+argc] mov [ebp+var_8], 0 mov [ebp+var_C], 12345678h lea edx, [ebp+var_C] mov [ebp+var_10], edx ; p1 mov esi, edx mov [ebp+var_14], esi ; p2 mov [ebp+var_18], edx ; p3 mov edx, [ebp+var_10] ; 取参数1 地址 mov edx, [edx] ; 取值 lea esi, a08x ; "%08x \r\n" mov [esp+34h+var_34], esi ; 参数1 "%08x\r\n" mov [esp+34h+var_30], edx ; 参数2 *p1 mov [ebp+var_1C], eax ; 这个和下面一行并未使用,可能是调试版本保存的中间变量吧。 mov [ebp+var_20], ecx call sub_401090 ; 调用 printf mov ecx, [ebp+var_14] movsx ecx, byte ptr [ecx] lea edx, a08x ; "%08x \r\n" mov [esp+34h+var_34], edx mov [esp+34h+var_30], ecx ; 同理没用 mov [ebp+var_24], eax call sub_401090 mov ecx, [ebp+var_18] movsx ecx, word ptr [ecx] lea edx, a08x ; "%08x \r\n" mov [esp+34h+var_34], edx mov [esp+34h+var_30], ecx ; 同理没用 mov [ebp+var_28], eax call sub_401090 xor ecx, ecx mov [ebp+var_2C], eax mov eax, ecx add esp, 30h pop esi pop ebp retn _main endp ``` ```asm ; x64 vs ; int __cdecl main(int argc, const char **argv, const char **envp) main proc near var_28= dword ptr -28h var_20= qword ptr -20h var_18= qword ptr -18h var_10= qword ptr -10h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx mov [rsp+arg_0], ecx sub rsp, 48h mov [rsp+48h+var_28], 12345678h lea rax, [rsp+48h+var_28] mov [rsp+48h+var_20], rax lea rax, [rsp+48h+var_28] mov [rsp+48h+var_18], rax lea rax, [rsp+48h+var_28] mov [rsp+48h+var_10], rax mov rax, [rsp+48h+var_20] ; 取出地址 mov edx, [rax] ; 取出 4 字节,x64的调用方式是 fastcall,所以这里前两个参数是 rcx,rdx lea rcx, Format ; "%08x \r\n" call printf mov rax, [rsp+48h+var_18] movsx eax, byte ptr [rax] mov edx, eax ; 取出 1 字节 lea rcx, a08x_0 ; "%08x \r\n" call printf mov rax, [rsp+48h+var_10] movsx eax, word ptr [rax] ; 取出 2 字节 mov edx, eax lea rcx, a08x_1 ; "%08x \r\n" call printf xor eax, eax add rsp, 48h retn main endp ``` ```asm ; x64 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public main main proc near var_1C= dword ptr -1Ch var_18= qword ptr -18h var_10= qword ptr -10h var_8= qword ptr -8 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 40h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main mov [rbp+var_1C], 12345678h lea rax, [rbp+var_1C] mov [rbp+var_8], rax lea rax, [rbp+var_1C] mov [rbp+var_10], rax lea rax, [rbp+var_1C] mov [rbp+var_18], rax mov rax, [rbp+var_8] mov eax, [rax] mov edx, eax ; 参数2 四字节 lea rcx, Format ; "%08x \r\n" ; 参数 1 call printf mov rax, [rbp+var_10] movzx eax, byte ptr [rax] ; 1 字节 movsx eax, al mov edx, eax lea rcx, Format ; "%08x \r\n" call printf mov rax, [rbp+var_18] movzx eax, word ptr [rax] ; 2 字节 cwde mov edx, eax lea rcx, Format ; "%08x \r\n" call printf mov eax, 0 add rsp, 40h pop rbp retn main endp ``` ```asm ; x64 clang ; int __cdecl main(int argc, const char **argv, const char **envp) main proc near var_3C= dword ptr -3Ch var_38= dword ptr -38h var_34= dword ptr -34h var_30= qword ptr -30h var_28= qword ptr -28h var_20= qword ptr -20h var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 68h mov [rsp+68h+var_4], 0 mov [rsp+68h+var_10], rdx mov [rsp+68h+var_14], ecx mov [rsp+68h+var_18], 12345678h lea rdx, [rsp+68h+var_18] mov [rsp+68h+var_20], rdx mov rax, rdx mov [rsp+68h+var_28], rax mov [rsp+68h+var_30], rdx mov rax, [rsp+68h+var_20] mov edx, [rax] lea rcx, a08x ; "%08x \r\n" call sub_140001090 mov rcx, [rsp+68h+var_28] movsx edx, byte ptr [rcx] lea rcx, a08x ; "%08x \r\n" mov [rsp+68h+var_34], eax ; 返回值保存没有用到 call sub_140001090 mov rcx, [rsp+68h+var_30] movsx edx, word ptr [rcx] lea rcx, a08x ; "%08x \r\n" mov [rsp+68h+var_38], eax ; 返回值保存但是没用 call sub_140001090 xor edx, edx mov [rsp+68h+var_3C], eax ; 返回值保存但是没用 mov eax, edx add rsp, 68h retn main endp ``` - 这些都是 debug 版本,有很多冗余操作 - **指针类型都只支持加法和减法。** - 指针加 1 后,指针内保存的地址值并不一定会加 1,运算结果取决于指针类型,如指针类型为 int,地址值将会加 4,这个 4 是根据类型大小所得到的值。当指针中保存的地址为数组首地址时,为了能够利用指针加 1 后访问到数组内下一成员,所以**加的是类型长度,而非数字 1。**如下例所示: ```c #include <stdio.h> int main(int argc, char* argv[]) { char ary[5] = {(char)0x01, (char)0x23, (char)0x45, (char)0x67, (char)0x89}; int *p1 = (int*)ary; char *p2 = (char*)ary; short *p3 = (short*)ary; p1 += 1; p2 += 1; p3 += 1; return 0; } ``` ```asm x86 x86 ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_18= dword ptr -18h var_14= dword ptr -14h var_10= dword ptr -10h var_C= byte ptr -0Ch var_B= byte ptr -0Bh var_A= byte ptr -0Ah var_9= byte ptr -9 var_8= byte ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 18h mov eax, ___security_cookie xor eax, ebp mov [ebp+var_4], eax ; 缓冲区溢出检查代码 mov [ebp+var_C], 1 ; arr[0]=1 mov [ebp+var_B], 23h ; '#' ; ary[1]=0x23 mov [ebp+var_A], 45h ; 'E' ; ary[2]=0x45 mov [ebp+var_9], 67h ; 'g' ; ary[3]=0x67 mov [ebp+var_8], 89h ; ary[4]=0x89 lea eax, [ebp+var_C] mov [ebp+var_10], eax ; p1= (int*)ary lea ecx, [ebp+var_C] mov [ebp+var_14], ecx ; p2 = (char*)ary lea edx, [ebp+var_C] mov [ebp+var_18], edx ; p3 = (short*)ary mov eax, [ebp+var_10] add eax, 4 ; 4 是 int 类型的长度 mov [ebp+var_10], eax mov ecx, [ebp+var_14] ; p1 += 1 add ecx, 1 ; 1 是 char 类型的长度 mov [ebp+var_14], ecx mov edx, [ebp+var_18] ; p2 += 1 add edx, 2 ; 2 是 short 类型的长度 mov [ebp+var_18], edx xor eax, eax ; eax 清零 mov ecx, [ebp+var_4] ; p3 += 1 xor ecx, ebp ; StackCookie call @__security_check_cookie@4 ; __security_check_cookie(x) ; 缓冲区溢出检查代码 mov esp, ebp pop ebp retn _main endp ``` ```asm x86 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 20h call ___main mov byte ptr [esp+0Fh], 1 mov byte ptr [esp+10h], 23h ; '#' mov byte ptr [esp+11h], 45h ; 'E' mov byte ptr [esp+12h], 67h ; 'g' mov byte ptr [esp+13h], 89h lea eax, [esp+0Fh] mov [esp+1Ch], eax lea eax, [esp+0Fh] mov [esp+18h], eax lea eax, [esp+0Fh] mov [esp+14h], eax add dword ptr [esp+1Ch], 4 add dword ptr [esp+18h], 1 add dword ptr [esp+14h], 2 mov eax, 0 leave retn _main endp ``` ```asm x86 clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_2C= dword ptr -2Ch var_28= dword ptr -28h var_24= dword ptr -24h var_20= dword ptr -20h var_1C= dword ptr -1Ch var_15= dword ptr -15h var_11= byte ptr -11h var_10= dword ptr -10h argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ebx push edi push esi sub esp, 20h mov eax, [ebp+argv] mov ecx, [ebp+argc] xor edx, edx lea esi, [ebp+var_15] mov [ebp+var_10], 0 mov edi, ds:dword_40D150 mov [ebp+var_15], edi ; ary[]= {1, 0x23, 0x45, 0x67} mov bl, ds:byte_40D154 mov [ebp+var_11], bl ; ary[4] = 0x89 mov edi, esi mov [ebp+var_1C], edi mov [ebp+var_20], esi mov [ebp+var_24], esi ; 3 个 赋值操作 mov esi, [ebp+var_1C] add esi, 4 mov [ebp+var_1C], esi mov esi, [ebp+var_20] add esi, 1 mov [ebp+var_20], esi mov esi, [ebp+var_24] add esi, 2 mov [ebp+var_24], esi mov [ebp+var_28], eax mov eax, edx mov [ebp+var_2C], ecx add esp, 20h pop esi pop edi pop ebx pop ebp retn _main endp ``` ```asm x64 vs ; int __cdecl main(int argc, const char **argv, const char **envp) main proc near var_38= qword ptr -38h var_30= qword ptr -30h var_28= qword ptr -28h var_20= byte ptr -20h var_1F= byte ptr -1Fh var_1E= byte ptr -1Eh var_1D= byte ptr -1Dh var_1C= byte ptr -1Ch var_18= qword ptr -18h arg_0= dword ptr 8 arg_8= qword ptr 10h ; __unwind { // __GSHandlerCheck mov [rsp+arg_8], rdx ; 保存argv到预留栈空间,fastcall mov [rsp+arg_0], ecx ; 保存argc到预留栈空间 sub rsp, 38h mov rax, cs:__security_cookie xor rax, rsp mov [rsp+38h+var_18], rax ; 缓冲区溢出检查代码 mov [rsp+38h+var_20], 1 mov [rsp+38h+var_1F], 23h ; '#' mov [rsp+38h+var_1E], 45h ; 'E' mov [rsp+38h+var_1D], 67h ; 'g' mov [rsp+38h+var_1C], 89h ;依次赋值给 ary lea rax, [rsp+38h+var_20] mov [rsp+38h+var_38], rax lea rax, [rsp+38h+var_20] mov [rsp+38h+var_30], rax lea rax, [rsp+38h+var_20] mov [rsp+38h+var_28], rax ; p1 - p3 赋值 mov rax, [rsp+38h+var_38] add rax, 4 mov [rsp+38h+var_38], rax mov rax, [rsp+38h+var_30] inc rax mov [rsp+38h+var_30], rax mov rax, [rsp+38h+var_28] add rax, 2 mov [rsp+38h+var_28], rax ; 三个指针 +1 的操作。 xor eax, eax mov rcx, [rsp+38h+var_18] xor rcx, rsp ; StackCookie call __security_check_cookie add rsp, 38h retn ; } // starts at 140001000 main endp ``` ```asm x64 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public main main proc near var_1D= byte ptr -1Dh var_1C= byte ptr -1Ch var_1B= byte ptr -1Bh var_1A= byte ptr -1Ah var_19= byte ptr -19h var_18= qword ptr -18h var_10= qword ptr -10h var_8= qword ptr -8 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 40h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main ; 调用初始化函数 mov [rbp+var_1D], 1 mov [rbp+var_1C], 23h ; '#' mov [rbp+var_1B], 45h ; 'E' mov [rbp+var_1A], 67h ; 'g' mov [rbp+var_19], 89h lea rax, [rbp+var_1D] mov [rbp+var_8], rax lea rax, [rbp+var_1D] mov [rbp+var_10], rax lea rax, [rbp+var_1D] mov [rbp+var_18], rax add [rbp+var_8], 4 add [rbp+var_10], 1 add [rbp+var_18], 2 mov eax, 0 add rsp, 40h pop rbp retn main endp ``` - 比前面一个好理解。 ```asm x64 clang ; int __cdecl main(int argc, const char **argv, const char **envp) main proc near var_38= qword ptr -38h var_30= qword ptr -30h var_28= qword ptr -28h var_19= dword ptr -19h var_15= byte ptr -15h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 38h xor eax, eax lea r8, [rsp+38h+var_19] mov [rsp+38h+var_4], 0 mov [rsp+38h+var_10], rdx mov [rsp+38h+var_14], ecx mov ecx, cs:dword_14000D2C0 mov [rsp+38h+var_19], ecx mov r9b, cs:byte_14000D2C4 mov [rsp+38h+var_15], r9b mov rdx, r8 mov [rsp+38h+var_28], rdx mov [rsp+38h+var_30], r8 mov [rsp+38h+var_38], r8 mov rdx, [rsp+38h+var_28] add rdx, 4 mov [rsp+38h+var_28], rdx mov rdx, [rsp+38h+var_30] add rdx, 1 mov [rsp+38h+var_30], rdx mov rdx, [rsp+38h+var_38] add rdx, 2 mov [rsp+38h+var_38], rdx add rsp, 38h retn main endp ``` ``` type *p; // 这里用 type 泛指某类型的指针 // 省略指针赋值代码 p+n 的目标地址 = 首地址 + sizeof( 指针类型 type) * n ``` - 对于偏移量为负数的情况,此公式**同样适用**。 - **两指针做减法操作是在计算两个地址之间的元素个数,结果为有符号整数。** ``` type *p, *q; // 这里用type泛指某类型的指针 // 省略指针赋值代码 p-q = ((int)p - (int)q) / sizeof(指针类型type) ``` - 两指针相加也是没有意义的。 ### 引用 - 引用类型实际上就是指针类型,只不过用于存放地址的内存空间对使用者而言是隐藏的。 - 在 C++中,除了引用是通过编译器实现寻址,而指针需要手动寻址外,**引用和指针没有太大区别**。**在反汇编下,没有引用这种数据类型。** ```c #include <stdio.h> void add(int &ref){ ref++; } int main(int argc, char* argv[]) { int n = 0x12345678; int &ref = n; add(ref); return 0; } /* 结果是 12345679 */ ``` ```asm x86 vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 8 mov [ebp+var_4], 12345678h ; n = 0x12345678 lea eax, [ebp+var_4] ; &ref = n mov [ebp+var_8], eax mov ecx, [ebp+var_8] push ecx call sub_401000 add esp, 4 ; 栈平衡 xor eax, eax mov esp, ebp pop ebp retn _main endp sub_401000 proc near arg_0= dword ptr 8 push ebp mov ebp, esp mov eax, [ebp+arg_0] mov ecx, [eax] ; 取出参数 ref 的内容放入 eax add ecx, 1 ; ecx 加 1 mov edx, [ebp+arg_0] mov [edx], ecx ; 再赋值回去,对eax做取内容操作,间接访问实参 pop ebp retn sub_401000 endp ``` ```asm x86 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 20h call ___main mov dword ptr [esp+18h], 12345678h ; n = 12345678 lea eax, [esp+18h] ; eax= &n mov [esp+1Ch], eax ; [esp+1Ch]存放n的地址,int& ref = n mov eax, [esp+1Ch] mov [esp], eax ; int * call __Z3addRi ; add(int &) mov eax, 0 leave retn _main endp ; _DWORD __cdecl add(int *) public __Z3addRi __Z3addRi proc near arg_0= dword ptr 8 push ebp mov ebp, esp mov eax, [ebp+arg_0] ; 取出参数 ref 的内容放入 eax mov eax, [eax] lea edx, [eax+1] ; 在这里计算的 +1。 mov eax, [ebp+arg_0] mov [eax], edx ; 对 eax 做取内容操作,间接访问实参 nop pop ebp retn __Z3addRi endp ``` ```asm x86 clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_18= dword ptr -18h var_14= dword ptr -14h var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 18h mov eax, [ebp+argv] mov ecx, [ebp+argc] mov [ebp+var_4], 0 mov [ebp+var_8], 12345678h ; n=12345678 lea edx, [ebp+var_8] ; edx=&n mov [ebp+var_C], edx ; [ebp-0Ch]存放 n 的地址,int& ref = n mov edx, [ebp+var_C] mov [esp+18h+var_18], edx mov [ebp+var_10], eax mov [ebp+var_14], ecx call sub_401000 xor eax, eax add esp, 18h pop ebp retn _main endp sub_401000 proc near var_4= dword ptr -4 arg_0= dword ptr 8 push ebp mov ebp, esp push eax mov eax, [ebp+arg_0] mov ecx, [ebp+arg_0] ; 取出参数 ref 的内容放入 ecx mov edx, [ecx] add edx, 1 mov [ecx], edx ; 对 ecx 做取内容操作,间接访问实参 mov [ebp+var_4], eax add esp, 4 pop ebp retn sub_401000 endp ``` ```asm x64 vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h var_10= qword ptr -10h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx mov [rsp+arg_0], ecx sub rsp, 38h mov [rsp+38h+var_18], 12345678h lea rax, [rsp+38h+var_18] mov [rsp+38h+var_10], rax mov rcx, [rsp+38h+var_10] call sub_140001000 xor eax, eax add rsp, 38h retn main endp sub_140001000 proc near arg_0= qword ptr 8 mov [rsp+arg_0], rcx mov rax, [rsp+arg_0] mov eax, [rax] inc eax ; 将指定的操作数加1,并将结果存回原位置 mov rcx, [rsp+arg_0] mov [rcx], eax retn sub_140001000 endp ``` ```asm x64 gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near var_C= dword ptr -0Ch var_8= qword ptr -8 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 30h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main mov [rbp+var_C], 12345678h lea rax, [rbp+var_C] mov [rbp+var_8], rax mov rax, [rbp+var_8] mov rcx, rax ; int * call _Z3addRi ; add(int &) mov eax, 0 add rsp, 30h pop rbp retn main endp ; __int64 __fastcall add(int *) public _Z3addRi _Z3addRi proc near arg_0= qword ptr 10h push rbp mov rbp, rsp mov [rbp+arg_0], rcx mov rax, [rbp+arg_0] mov eax, [rax] lea edx, [rax+1] mov rax, [rbp+arg_0] mov [rax], edx nop pop rbp retn _Z3addRi endp ``` ```asm x64 clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_20= qword ptr -20h var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 48h mov [rsp+48h+var_4], 0 mov [rsp+48h+var_10], rdx mov [rsp+48h+var_14], ecx mov [rsp+48h+var_18], 12345678h lea rdx, [rsp+48h+var_18] mov [rsp+48h+var_20], rdx mov rcx, [rsp+48h+var_20] call sub_140001000 xor eax, eax add rsp, 48h retn main endp sub_140001000 proc near var_8= qword ptr -8 push rax mov [rsp+8+var_8], rcx mov rcx, [rsp+8+var_8] mov eax, [rcx] add eax, 1 mov [rcx], eax pop rax retn sub_140001000 endp ``` - x64 和 x86 差不多。 - 通过案例可知,在反汇编下,没有引用这种数据类型。所以引用类型也可以作为函数的参数类型和返回类型使用。 ## 常量 - 常量是一个恒定不变的值,它**在内存中也是不可修改的**。常量数据在程序运行前就已经存在,它们**被编译到可执行文件中,当程序启动后,它们便会被加载进来**。这些数据通常都会保存在**常量数据区中,该区的属性没有写权限**,所以在对常量进行修改时,程序会报错。试图修改常量数据都将引发异常,导致程序崩溃。 ### 常量的定义 - 在 C++中,可以使用宏机制#define 来定义常量,也可以使用 const 将**变量**定义为一个常量。**\#define 定义常量名称,编译器在对其进行编译时,会将代码中的宏名称替换成对应信息**。宏的使用可以增加代码的可读性。**const 是为了增加程序的健壮性而存在的**。 ### #define 和 const 的区别 - **\#define 修饰的符号名称是一个真量数值,而 const 修饰的栈常量,是一个“假”常量**。const 定义的实际上还是变量,只是由编译器检查是否有修改行为,有修改行为就会编译报错。**被 const 修饰过的栈变量本质上是可以被修改的**。我们可以利用指针获取 const 修饰过的栈变量地址,强制将 const 属性修饰去掉。 ```c #include <stdio.h> int main(int argc, char* argv[]) { const int n1 = 5; int *p = (int*)&n1; *p = 6; int n2 = n1; return 0; } /* 运行结果 n1 = 6 n2 = 5 别奇怪就是这个结果,下面会说 */ ``` ```asm x86 vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_C= dword ptr -0Ch var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 0Ch mov [ebp+var_4], 5 ; n1=5 lea eax, [ebp+var_4] ; eax = &n1 mov [ebp+var_8], eax ; *p = (int*)&n1 mov ecx, [ebp+var_8] mov dword ptr [ecx], 6 ; *p = 6 mov [ebp+var_C], 5 ; 注意这里对应的代码是 n2=n1,编译器自动替换成 n2=5 xor eax, eax mov esp, ebp pop ebp retn _main endp ``` ```asm x86 gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 10h call ___main mov dword ptr [esp+4], 5 lea eax, [esp+4] mov [esp+0Ch], eax mov eax, [esp+0Ch] mov dword ptr [eax], 6 mov dword ptr [esp+8], 5 mov eax, 0 leave retn _main endp ``` ```asm x86 clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push esi sub esp, 18h mov eax, [ebp+argv] mov ecx, [ebp+argc] xor edx, edx mov [ebp+var_8], 0 mov [ebp+var_C], 5 lea esi, [ebp+var_C] mov [ebp+var_10], esi mov esi, [ebp+var_10] mov dword ptr [esi], 6 mov [ebp+var_14], 5 mov [ebp+var_18], eax mov eax, edx mov [ebp+var_1C], ecx add esp, 18h pop esi pop ebp retn _main endp ``` ```asm x64 vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx mov [rsp+arg_0], ecx sub rsp, 18h mov [rsp+18h+var_18], 5 lea rax, [rsp+18h+var_18] mov [rsp+18h+var_10], rax mov rax, [rsp+18h+var_10] mov dword ptr [rax], 6 mov [rsp+18h+var_14], 5 xor eax, eax add rsp, 18h retn main endp ``` ```asm x64 gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= qword ptr -8 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 30h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main mov [rbp+var_10], 5 lea rax, [rbp+var_10] mov [rbp+var_8], rax mov rax, [rbp+var_8] mov dword ptr [rax], 6 mov [rbp+var_C], 5 mov eax, 0 add rsp, 30h pop rbp retn main endp ``` ```asm x64 clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_24= dword ptr -24h var_20= qword ptr -20h var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 28h xor eax, eax mov [rsp+28h+var_4], 0 mov [rsp+28h+var_10], rdx mov [rsp+28h+var_14], ecx mov [rsp+28h+var_18], 5 lea rdx, [rsp+28h+var_18] mov [rsp+28h+var_20], rdx mov rdx, [rsp+28h+var_20] mov dword ptr [rdx], 6 mov [rsp+28h+var_24], 5 add rsp, 28h retn main endp ``` - 这部分汇编非常简单,编译器在编译过程中发现 n1 的初始值是可知的,并且被修饰为 const。之后所有使用 n1 的地方都**替换为这个可预知值**,所以 n2=n1 对应的汇编代码没有将 n1 赋值给 n2,而是用常量值 5 代替。 | #define | const | | :-----: | :-----: | | 在编译期间查找替换 | 在编译期间检查 const 修饰的变量是否被修改 | | 由系统判断是否被修改 | 由编译器限制修改 | | 字符串定义在文件只读数据区,数据常量编译为立即数寻址方式,成为二进制代码的一部分 | 根据作用域决定所在的内存位置和属性 | ## 总结 - 计算机的工作流程归根结底是输入→处理→输出的过程,而数据正是被处理的对象。对数据的考察有两点:**在何处**和**如何解释**。 1. **在何处**:先查看地址,有了内存地址,才能有内存属性。藉此,可以知道此数据是否为变量(可读写)、是否为常量(只读)、是否为代码(可执行)等。还可以考察进程在内存的布局,如栈区、堆区、全局区、代码区等,藉此,又可以知道数据的作用域。 2. **如何解释**:“大端方式”还是“小端方式”。
别卷了
2025年8月25日 13:54
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码