C++ 反汇编
配套资源下载
环境及工具
反汇编引擎工作原理(可略过)
基本数据类型的表现形式
程序的真正入口
各种表达式的求值过程
本文档使用 MrDoc 发布
-
+
首页
各种表达式的求值过程
**<center>这部分很长,慢慢看</center>** ---------------- ## 算术运算和赋值 - 包含了加法、减法、乘法和除法和“等于”。 ### 各种算术运算的工作形式 #### 加法 - 编译器中常用的优化方案有如下两种。 1. **01选项:生成文件占用空间最少**。 2. **02选项:执行效率最快**。 - 在 VS 中,Release 编译选项组的默认选项为 02 选项 - 在 Debug 编译选项中,使用的是 Od+ZI 选项,此选项使编译器产生的一切代码都以便于调试为根本前提,甚至为了便于单步跟踪以及源码和目标代码块的对应阅读,不惜增加冗余代码。 - 这里将对 Release 和 Debug 版本进行对比,分析其优化方式,便于日后还原代码。 - 在使用Debug编译选项组时,产生的目标汇编代码和源码是一一对应的。以加法运算为例,分别使用不同类型的操作数查看在Debug编译选项组下编译后对应的汇编代码。 ```c #include <stdio.h> int main(int argc, char* argv[]) { 15+20; //无效语句,不参与编译 int n1 = 0; //变量定义 int n2 = 0; n1 = n1 + 1; //变量加常量的加法运算 n1 = 1 + 2; //两个常量相加的加法运算 n1 = n1 + n2; //两个变量相加的加法运算 printf("n1 = %d\n", n1); return 0; } ``` ```asm x86 debug vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 8 mov [ebp+var_4], 0 ; n1 = 0 mov [ebp+var_8], 0 ; n2 = 0 mov eax, [ebp+var_4] add eax, 1 mov [ebp+var_4], eax ; n1 = n1 + 1 mov [ebp+var_4], 3 ; n1 = 3 mov ecx, [ebp+var_4] add ecx, [ebp+var_8] mov [ebp+var_4], ecx ; n1 - n1 + n2 mov edx, [ebp+var_4] push edx ; 参数2,n1入栈 push offset aN1D ; 参数1,"n1 = %d\n" 入栈 call sub_401090 ; 调用 printf add esp, 8 xor eax, eax mov esp, ebp pop ebp retn _main endp ``` ```asm x86 debug gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 20h call ___main mov dword ptr [esp+1Ch], 0 ; n1 = 0 mov dword ptr [esp+18h], 0 ; n2 = 0 add dword ptr [esp+1Ch], 1 ; n1 = 1 mov dword ptr [esp+1Ch], 3 ; n2 = 3 mov eax, [esp+18h] add [esp+1Ch], eax ; n1 = n1 + n2 mov eax, [esp+1Ch] mov [esp+4], eax ; 参数2,n1入栈 mov dword ptr [esp], offset Format ;参数1,"n1 = %d\n"入栈 call _printf mov eax, 0 leave retn _main endp ``` ```asm x86 debug clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_24= dword ptr -24h var_20= dword ptr -20h var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push esi sub esp, 20h mov eax, [ebp+argv] mov ecx, [ebp+argc] mov [ebp+var_8], 0 ; n1 = 0 mov [ebp+var_C], 0 ; n2 = 0 mov [ebp+var_10], 0 mov edx, [ebp+var_C] add edx, 1 mov [ebp+var_C], edx ; n1 = n1 + 1 mov [ebp+var_C], 3 ; n1 = 3 mov edx, [ebp+var_C] add edx, [ebp+var_10] mov [ebp+var_C], edx ; n1 = n1 + n2 mov edx, [ebp+var_C] lea esi, aN1D ; "n1 = %d\n" mov [esp+24h+var_24], esi ; 参数1入栈,存入esp mov [esp+24h+var_20], edx ; 参数2入栈,存入esp-04h mov [ebp+var_14], eax mov [ebp+var_18], ecx call sub_401070 ; 调用 printf 函数 xor ecx, ecx mov [ebp+var_1C], eax mov eax, ecx add esp, 20h pop esi pop ebp retn _main endp ``` ```asm x64 debug vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h var_14= dword ptr -14h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx mov [rsp+arg_0], ecx sub rsp, 38h mov [rsp+38h+var_18], 0 ; n1 = 0 mov [rsp+38h+var_14], 0 ; n2 = 0 mov eax, [rsp+38h+var_18] inc eax mov [rsp+38h+var_18], eax ; n1 = n1 + 1 mov [rsp+38h+var_18], 3 ; n2 = 3 mov eax, [rsp+38h+var_14] mov ecx, [rsp+38h+var_18] add ecx, eax mov eax, ecx mov [rsp+38h+var_18], eax ; n1 = n1 + n2 mov edx, [rsp+38h+var_18] ; 参数2 入 edx lea rcx, Format ; "n1 = %d\n" ; 参数1 入 ecx call printf xor eax, eax add rsp, 38h retn main endp ``` ```asm x64 debug gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near var_8= dword ptr -8 var_4= dword ptr -4 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 30h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main ; 调用初始化函数,一次性初始化守卫。确保 C++全局和静态对象的构造函数在程序生命周期内,只被安全地、正确地执行一次(一定干,只干一次)。 mov [rbp+var_4], 0 ; n1 = 0 mov [rbp+var_8], 0 ; n2 = 0 add [rbp+var_4], 1 ; n1 = n1 + 1 mov [rbp+var_4], 3 ; n1 = 3 mov eax, [rbp+var_8] add [rbp+var_4], eax ; n1 = n1 + n2 mov eax, [rbp+var_4] mov edx, eax ; 参数2 入 edx lea rcx, Format ; 参数1 入 ecx "n1 = %d\n" call printf mov eax, 0 add rsp, 30h pop rbp retn main endp ``` ```asm x64 debug clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_20= dword ptr -20h var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 48h mov [rsp+48h+var_4], 0 mov [rsp+48h+var_10], rdx mov [rsp+48h+var_14], ecx mov [rsp+48h+var_18], 0 ; n1 = 0 mov [rsp+48h+var_1C], 0 ; n2 = 0 mov ecx, [rsp+48h+var_18] add ecx, 1 mov [rsp+48h+var_18], ecx ; n1 = n1 + 1 mov [rsp+48h+var_18], 3 ; n2 = 3 mov ecx, [rsp+48h+var_18] add ecx, [rsp+48h+var_1C] mov [rsp+48h+var_18], ecx ; n1 = n1 + n2 mov edx, [rsp+48h+var_18] ; 参数2 入 edx lea rcx, aN1D ; "n1 = %d\n" ; 参数1 人 rcx call sub_140001070 xor edx, edx mov [rsp+48h+var_20], eax mov eax, edx add rsp, 48h retn main endp ``` - 可以观察到,两个常量相加,编译器**在编译期间会计算出结果,将这个结果作为立即数参与运算**,减少了程序在运行期的计算。 - **开启02选项后,编译出来的汇编代码会有较大的变化**。由于效率优先,编译器会**将无用代码去除,并对可合并代码进行归并处理**。入前面代码的n1 = n1 + 1;会被去除。因为在其后又重新对变量n1进行了赋值操作,而在此之前没有对变量n1做任何访问,所以编译器判定此句代码是可被删除的。 - 编译器常用两种优化策略: 1. **常量传播**:将编译期间可计算出结果的变量转换成常量,这样就减少了变量 的使用。代码如下所示: ```c int main(int argc, char* argv[]){ int n = 1; printf("n= %d\n", n); return 0; } ``` - 变量n是一个在编译期间可以计算出结果的变量。所以直接用常量 1 替代。 ```c // 优化后: int main(int argc, char* argv[]){ printf("n= %d\n", 1); return 0; } ``` 3. **常量折叠**:当出现多个常量进行计算,且编译器可以在编译期间计算出结果 时,源码中所有的常量计算都将被计算结果代替。如下所示: ```c int main(int argc, char* argv[]){ int n= 1 + 5 - 3 * 6; printf("n= %d\n", n); return 0; } ``` - 此时不会生成计算指令,因为“1+5-3×6”的值是可以在编译过程中计算出来的。 ```c int main(int argc, char* argv[]){ int n= -12; printf("n= %d\n", n); return 0; } ``` - 现在变量n为在编译期间可计算出结果的变量,那么接下来**组合使用常量传播对其进行常量转换**就是合理的,程序中将不会出现变量 n,而是直接以常量-12 代替。 ```c int main(int argc, char* argv[]){ printf("n= %d\n", -12); return 0; } ``` - 在前面的第一个示例中,变量 n1 和 n2 的初始值是一个常量,VC++编译器在开启 02 优化方案后,会尝试使用常量替换变量。如果在程序的逻辑中,**声明的变量没有被修改过,而且上下文中不存在针对此变量的取地址和间接访问操作,那么这个变量就等价于常量**,编译器就认为可以删除这个变量,直接用常量代替。 ```c int n1 = 0; // 常量化以后,n1用0代替了 int n2 = 0; // 同上,这句也没有了 // 变量加常量的加法运算 n1 = n1 + 1; // n1 = 0 + 1; // 两常量相加的加法运算 n1 = 1 + 2; // n1 = 1 + 2; n1 = n1 + n2; // n1 = n1 + 0; printf("n1 = %d\n", n1); // 变为 n1 = 0 + 1; // 优化过程: n1 = 0 + 1;被删除了 n1 = 1 + 2; // n1 = 3;常量折叠 n1 = n1 + n2; // n1= 3 + 0; printf("n1= %d\n", n1); // 最终 printf("n1 = %d\n", 3); ``` - **因为变量转换成了常量,所以在编译期间可以直接计算出结果**,而“n1=0+1;”这句赋值代码之后又对 n1 再次赋值,所以这是一句对程序没有任何影响的代码,被剔除掉。后面的“n1=1+2;”满足常量折叠的条件,所以直接计算出了加法结果3,“n1=1+2”由此转变为“n1=3”,此时满足常量传播条件,对 n1 的引用转变为对常量 3 的引用,printf的参数引用了 n1,于是代码直接变为“printf("n1 =%d\n", 3);”下面是 Release 版本的反汇编: ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch push 3 push offset aN1D ; "n1 = %d\n" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 10h call ___main mov dword ptr [esp+4], 3 mov dword ptr [esp], offset aN1D ; "n1 = %d\n" call _printf xor eax, eax leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch push 3 push offset aN1D ; "n1 = %d\n" call sub_401020 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov edx, 3 lea rcx, aN1D ; "n1 = %d\n" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near arg_20= byte ptr 28h sub rsp, arg_20 call __main mov edx, 3 lea rcx, aN1D ; "n1 = %d\n" call printf xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h lea rcx, aN1D ; "n1 = %d\n" mov edx, 3 call sub_140001020 xor eax, eax add rsp, 28h retn main endp ``` - 可以明显看出来,都被优化成`printf("n1 = %d\n", 3);`了。 - 修改代码,将变量的初始值 0 修改为命令行参数的个数 arg c,让编译器无法在编译时计算出结果。 ```c #include <stdio.h> int main(int argc, char* argv[]) { int n1 = argc; // 修改处 int n2 = argc; // 修改处 n1 = n1 + 1; n1 = 1 + 2; n1 = n1 + n2; printf("n1 = %d\n", n1); return 0; } ``` - 由于没法在编译时计算出结果,所以程序中的变量就不会被常量替换掉。分析下优化过程: ```c int main(int argc, char* argv[]){ // int n1 = argc; 在后面的代码中被常量代替 // int n2 = argc; 虽然不能用常量代替,但是因为之后没有对n2进行修改,所以引用n2等价于引用argc,n2则被删除,这种方法称为复写传播 // n1 = n1 + 1; 其后即刻重新对n1赋值,这句被删除了 // n1 = 1 + 2; 常量折叠,等价于n1 = 3; // n1 = n1 + n2; 常量传播和复写传播,等价于n1 = 3 + argc; // printf("n1 = %d\n", n1); // 其后n1没有被访问,可以用3 + argc代替 printf("n1 = %d\n", 3 + argc); return 0; } ``` - 上述程序的 Release 版本代码如下: ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] add eax, 3 push eax push offset aN1D ; "n1 = %d\n" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] add eax, 3 push eax push offset aN1D ; "n1 = %d\n" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] add eax, 3 push eax push offset aN1D ; "n1 = %d\n" call sub_401020 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h lea edx, [rcx+3] lea rcx, aN1D ; "n1 = %d\n" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main lea edx, [rbx+3] lea rcx, aN1D ; "n1 = %d\n" call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h lea edx, [rcx+3] lea rcx, aN1D ; "n1 = %d\n" call sub_140001020 xor eax, eax add rsp, 28h retn main endp ``` #### 减法 - 减法运算对应汇编指令 SUB,虽然**计算机只会做加法,但是可以通过补码转换将减法转变为加法的形式实现**。反码的原理如下: ``` Y + Y(反) = 11111111B Y + Y(反) + 1 = 0(进位丢失) ``` - 由上可得: ``` Y(反)+ 1 = 0 - Y<==>Y(反)+ 1 = -Y<==>Y(补)= -Y 如: Y(反)+ 1 = 0 - Y<==>Y(反)+ 1 = -Y<==>Y(补)= -Y ``` - 示例如下: ```c #include <stdio.h> int main(int argc, char* argv[]) { int n1 = argc; int n2 = 0; scanf("%d", &n2); n1 = n1 - 100; n1 = n1 + 5 - n2 ; printf("n1 = %d \r\n", n1); return 0; } ``` ```asm x86 debug vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 8 ; 栈平衡 mov eax, [ebp+argc] mov [ebp+var_4], eax ; n1 = argc mov [ebp+var_8], 0 ; n2 = 0 lea ecx, [ebp+var_8] push ecx ; 参数2:n2 入栈 push offset unk_417160 ; 参数1:"%d" 入栈 call sub_401110 ; 调用 scanf add esp, 8 mov edx, [ebp+var_4] ; edx = n1 sub edx, 64h ; 'd' ; edx = edx -100 mov [ebp+var_4], edx ; n1 = n1 - 100 mov eax, [ebp+var_4] add eax, 5 ; eax = n1 + 5 sub eax, [ebp+var_8] mov [ebp+var_4], eax ; n1=n1+5-n2 mov ecx, [ebp+var_4] push ecx ; 参数2:n1 push offset aN1D ; 参数1:"n1 = %d \r\n" call sub_4010D0 add esp, 8 xor eax, eax mov esp, ebp pop ebp retn _main endp ``` ```asm x86 debug gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 20h call ___main mov eax, [ebp+argc] mov [esp+1Ch], eax ; n1 mov dword ptr [esp+18h], 0 ; n2 lea eax, [esp+18h] mov [esp+4], eax ; 参数2 n2入栈 mov dword ptr [esp], offset Format ; 参数1 "%d"入栈 call _scanf sub dword ptr [esp+1Ch], 64h ; 'd' ; n1 = n1 - 100 mov eax, [esp+1Ch] lea edx, [eax+5] ; edx = n1 + 5 mov eax, [esp+18h] sub edx, eax ; edx = n1 +5 - n2 mov eax, edx mov [esp+1Ch], eax ; n1 = n1 + 5 - n2 mov eax, [esp+1Ch] mov [esp+4], eax mov dword ptr [esp], offset aN1D ; "n1 = %d \r\n" call _printf mov eax, 0 leave retn _main endp ``` ```asm x86 debug clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_24= dword ptr -24h var_20= dword ptr -20h var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 24h mov eax, [ebp+argv] mov ecx, [ebp+argc] mov [ebp+var_4], 0 ; return 0,因为[ebp]存储的是调用 main 函数的 ebp 地址,[ebp - 04h] 表示的就是上一个栈帧的栈顶。 mov edx, [ebp+argc] mov [ebp+var_8], edx ; n1 mov [ebp+var_C], 0 ; n2 lea edx, unk_417160 ; "%d" mov [esp+24h+var_24], edx ; 这里就是 [esp] 栈顶。 lea edx, [ebp+var_C] mov [esp+24h+var_20], edx ; 这里是[esp+04h] mov [ebp+var_10], eax ; 注意,这里是 10h,十六进制。保存eax 寄存器到栈中。 mov [ebp+var_14], ecx ; 同上一条,保存 ecx 寄存器到栈中,编译器为了安全,在调用外部函数前保存重要寄存器。 call sub_401080 ; scanf mov ecx, [ebp+var_8] ; ecx = n1 sub ecx, 64h ; 'd' ; ecx = n1 - 100 mov [ebp+var_8], ecx ; n1 = n1 -100 mov ecx, [ebp+var_8] ; ecx = n1 add ecx, 5 ; ecx = n1 + 5 sub ecx, [ebp+var_C] ; ecx = n1 + 5 - n2 mov [ebp+var_8], ecx ; n1 = n1 + 5 - n2 mov ecx, [ebp+var_8] lea edx, aN1D ; "n1 = %d \r\n" mov [esp+24h+var_24], edx mov [esp+24h+var_20], ecx mov [ebp+var_18], eax ; 这里保存 scanf 的返回值(eax 中),虽然C代码中没有使用这个返回值 call sub_4010E0 xor ecx, ecx mov [ebp+var_1C], eax mov eax, ecx add esp, 24h pop ebp retn _main endp ``` - **这个 x86 debug clang 值得一看**。 ```asm x64 debug vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h var_14= dword ptr -14h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx ; 注意这是 fastcall,第二个参数,argv 存入 rsp+arg_8 mov [rsp+arg_0], ecx ; 第一个参数,argc 存入 rsp+arg_0 sub rsp, 38h mov eax, [rsp+38h+arg_0] ; eax = argc mov [rsp+38h+var_18], eax ; n1 = argc mov [rsp+38h+var_14], 0 ; n2 = 0 lea rdx, [rsp+38h+var_14] ; 后面没啥说的 lea rcx, unk_1400182D0 call sub_140001180 mov eax, [rsp+38h+var_18] sub eax, 64h ; 'd' mov [rsp+38h+var_18], eax mov eax, [rsp+38h+var_18] add eax, 5 sub eax, [rsp+38h+var_14] mov [rsp+38h+var_18], eax mov edx, [rsp+38h+var_18] lea rcx, Format ; "n1 = %d \r\n" call printf xor eax, eax add rsp, 38h retn main endp ``` ```asm x64 debug gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near var_8= dword ptr -8 var_4= dword ptr -4 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 30h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main mov eax, [rbp+arg_0] mov [rbp+var_4], eax ; n1 = argc mov [rbp+var_8], 0 ; n2 = 0 lea rax, [rbp+var_8] mov rdx, rax lea rcx, Format ; "%d" call scanf sub [rbp+var_4], 64h ; 'd' mov eax, [rbp+var_4] lea edx, [rax+5] mov eax, [rbp+var_8] sub edx, eax mov eax, edx mov [rbp+var_4], eax mov eax, [rbp+var_4] mov edx, eax lea rcx, aN1D ; "n1 = %d \r\n" call printf mov eax, 0 add rsp, 30h pop rbp retn main endp ``` ```asm x64 debug clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_24= dword ptr -24h var_20= dword ptr -20h var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 48h ; 为局部变量分配48h(72字节)的栈空间 mov [rsp+48h+var_4], 0 ; 这个实际上并没有用到,意义未知。 mov [rsp+48h+var_10], rdx mov [rsp+48h+var_14], ecx mov ecx, [rsp+48h+var_14] mov [rsp+48h+var_18], ecx ; n1 mov [rsp+48h+var_1C], 0 ; n2 lea rcx, unk_1400182D0 lea rdx, [rsp+48h+var_1C] call sub_140001080 mov r8d, [rsp+48h+var_18] ; 64 位寄存器 r8的低 32 位部分。16 位是 r8w,8 位是 r8b。 sub r8d, 64h ; 'd' mov [rsp+48h+var_18], r8d mov r8d, [rsp+48h+var_18] add r8d, 5 sub r8d, [rsp+48h+var_1C] mov [rsp+48h+var_18], r8d mov edx, [rsp+48h+var_18] lea rcx, aN1D ; "n1 = %d \r\n" mov [rsp+48h+var_20], eax call sub_1400010F0 xor edx, edx mov [rsp+48h+var_24], eax mov eax, edx add rsp, 48h retn main endp ``` - 这里的 x64 debug clang,没有使用传统的栈帧管理方法,因为在 x64 体系中,默认使用__fastcall约定,前4个参数通过寄存器传递(rcx, rdx, r8, r9)栈的使用大大减少,编译器倾向于直接使用rsp进行偏移访问,节省指令和寄存器。 - 另外 x32 debug clang 的案例值得研究。 - 加数为负数时,执行的并非加法而是减法操作。 - 虽然书上说减法的 02 优化方式一致,但是本着严谨的态度,我们在这里也进行一些分析: ```c #include <stdio.h> int main(int argc, char* argv[]) { int n1 = argc; int n2 = 0; scanf("%d", &n2); n1 = n1 - 100; n1 = n1 + 5 - n2 ; printf("n1 = %d \r\n", n1); return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 8 mov eax, [ebp+argc] mov [ebp+var_4], eax ; n1 = argc mov [ebp+var_8], 0 ; n2 = 0 lea ecx, [ebp+var_8] push ecx push offset unk_417160 call sub_401110 add esp, 8 mov edx, [ebp+var_4] sub edx, 64h ; 'd' mov [ebp+var_4], edx ; n1 = n1 - 100 mov eax, [ebp+var_4] add eax, 5 sub eax, [ebp+var_8] mov [ebp+var_4], eax ; n1 = n1 + 5 - n2 mov ecx, [ebp+var_4] push ecx push offset aN1D ; "n1 = %d \r\n" call sub_4010D0 add esp, 8 xor eax, eax mov esp, ebp pop ebp retn _main endp ``` - 看起来没区别 ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 20h call ___main lea eax, [esp+1Ch] mov dword ptr [esp], offset aD ; "%d" mov [esp+4], eax ; n2 入栈 mov dword ptr [esp+1Ch], 0 ; n2 = 0 call _scanf mov eax, [ebp+argc] mov dword ptr [esp], offset aN1D ; "n1 = %d \r\n" sub eax, 5Fh ; '_' ; 常量传播变成 - 95 了 sub eax, [esp+1Ch] mov [esp+4], eax ; n1 直接用 eax 来代替了。 call _printf xor eax, eax leave retn _main endp ``` - 参数直接优化成用寄存器代替了 ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_8= dword ptr -8 argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch push esi push eax mov esi, [esp+8+argc] ; esi 就是 n1 mov eax, esp mov [esp+8+var_8], 0 ; n2 = 0 push eax push offset unk_417160 call sub_401040 add esp, 8 add esi, 0FFFFFFA1h ; 补码:实际上是 - 95,最高位的那个 0 是第九位,别看错了。 sub esi, [esp+8+var_8] push esi push offset aN1D ; "n1 = %d \r\n" call sub_401080 add esp, 8 xor eax, eax add esp, 4 pop esi retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h var_14= dword ptr -14h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx mov [rsp+arg_0], ecx sub rsp, 38h mov eax, [rsp+38h+arg_0] mov [rsp+38h+var_18], eax ; n1 mov [rsp+38h+var_14], 0 ; n2 = 0 lea rdx, [rsp+38h+var_14] lea rcx, unk_1400182D0 call sub_140001180 mov eax, [rsp+38h+var_18] sub eax, 64h ; 'd' mov [rsp+38h+var_18], eax mov eax, [rsp+38h+var_18] add eax, 5 sub eax, [rsp+38h+var_14] mov [rsp+38h+var_18], eax mov edx, [rsp+38h+var_18] lea rcx, Format ; "n1 = %d \r\n" call printf xor eax, eax add rsp, 38h retn main endp ``` - vs 几乎没有优化 ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near var_C= dword ptr -0Ch push rbx sub rsp, 30h mov ebx, ecx ; n1 = ecx,也就是argc call __main lea rdx, [rsp+38h+var_C] ; 先入栈 mov [rsp+38h+var_C], 0 ; 再赋值 lea rcx, aD ; "%d" call scanf lea edx, [rbx-5Fh] ; rbx 就是 n1,先将其 -5Fh,然后当作地址取值, ; 然后再将这个值的地址传给 edx,用一条指令完成的 sub 和 mov 指令 sub edx, [rsp+38h+var_C] lea rcx, aN1D ; "n1 = %d \r\n" call printf xor eax, eax add rsp, 30h pop rbx retn main endp ``` - 中间有一个对计算和赋值的优化方式注意一下。 ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_C= dword ptr -0Ch push rsi sub rsp, 30h mov esi, ecx ; n1 mov [rsp+38h+var_C], 0 ; n2 lea rcx, unk_1400182D0 lea rdx, [rsp+38h+var_C] call sub_140001040 lea edx, [rsi-5Fh] sub edx, [rsp+38h+var_C] lea rcx, aN1D ; "n1 = %d \r\n" call sub_1400010A0 xor eax, eax add rsp, 30h pop rsi retn main endp ``` - 没啥说的 #### 乘法 - 乘法汇编指令分为`有符号 imul`和`无符号 mul`。**结果存储在两个寄存器中**,因为两个 n 位数的乘积最多需要 2n 位来表示。。乘法执行周期较长,编译时会试图转为加法,或者使用**移位**等周期较短的指令。这两条指令的详细说明如下: ```asm MUL r/m8 ; 操作数是 8 位寄存器或内存地址,被乘数 AL,乘积 AX MUL r/m16 ; 操作数是 16 位寄存器或内存地址,被乘数 AX,乘积 DX:AX,高 16 在 DX,低 16 在 AX MUL r/m32 ; 操作数是 32 位寄存器或内存地址,被乘数 EAX,乘积 EDX:EAX,高 32 在 EDX,低 32 在 EAX MUL r/m64 ; 操作数是 64 位寄存器或内存地址 (x86-64),被乘数 RAX,乘积 RDX:RAX,高 64 在 RDX,低 64 在 RAX IMUL reg16, r/m16 ; reg16 = reg16 * r/m16 IMUL reg32, r/m32 ; reg32 = reg32 * r/m32 IMUL reg64, r/m64 ; reg64 = reg64 * r/m64 (x86-64) ; 三操作数的结果有一点区别 IMUL reg16, r/m16, imm8 ; reg16 = r/m16 * sign-extended imm8 IMUL reg16, r/m16, imm16 ; reg16 = r/m16 * imm16 IMUL reg32, r/m32, imm8 ; reg32 = r/m32 * sign-extended imm8 IMUL reg32, r/m32, imm32 ; reg32 = r/m32 * imm32 IMUL reg64, r/m64, imm8 ; reg64 = r/m64 * sign-extended imm8 (x86-64) IMUL reg64, r/m64, imm32 ; reg64 = r/m64 * sign-extended imm32 (x86-64) ``` - MUL 影响的标志位: - **CF (进位标志) 和 OF (溢出标志):如果乘积的高半部分(AH, DX, EDX, RDX)不为零,则 CF和 OF 都被置为 1**。这表示结果无法完全容纳在单个寄存器(AL, AX, EAX, RAX)中。 - **如果乘积的高半部分为零,则 CF和 OF都被清除为 0**。这表示结果完全容纳在低半部分寄存器中。 - SF, ZF, AF, PF:这些标志位的状态在 **MUL 指令执行后未定义**(Undefined)。你不能依赖它们执行后的值。 - IMUL 与 MUL 完全相同的寄存器使用规则(隐式使用 AL/AX/EAX/RAX 和 AH/DX/EDX/RDX)。 - 三操作数时的结果: - 将第二个操作数(源操作数,可以是寄存器或内存)乘以第三个操作数(立即数)。 - 结果被截断到目标寄存器(第一个操作数)的大小。 - **结果只存储低半部分!** 高半部分被丢弃。 - 目标寄存器和源操作数**必须大小相同**。 - 立即数会被符号扩展到与源操作数相同的位数(如果是 8 位立即数 `imm8`)。 |特性|MUL (无符号)|IMUL (有符号)| |---|---|---| |**操作数**|单操作数形式 (隐式累加器)|**三种形式:** <br>1. 单操作数 (隐式累加器) <br>2. 双操作数 (reg = reg * r/m) <br>3. 三操作数 (reg = r/m * imm)| |**结果存储**|**完整乘积:**总是存储在 DX:AX / EDX:EAX / RDX:RAX|**单操作数形式:** 完整乘积 (DX:AX / EDX:EAX / RDX:RAX) <br>**双/三操作数形式:** **截断乘积** (仅存目标寄存器低半部分)| |**溢出检测**|`CF=OF=1`表示高半部分非零 (即结果 > 单寄存器最大值)|**单操作数形式:** `CF=OF=1`表示高半部分包含有效位 (非全0或全1符号扩展) <br>**双/三操作数形式:** `CF=OF=1`表示截断 (实际结果超出目标寄存器有符号范围)| |**其他标志**|SF, ZF, AF, PF **未定义**|**单操作数形式:** SF, ZF, AF, PF **未定义** <br>**双/三操作数形式:** SF, ZF 等根据**截断后**的结果设置| |**主要用途**|无符号整数乘法|有符号整数乘法 <br>(双/三操作数形式常用于高效计算,即使结果可能截断)| - 下面时一个 debug 版本的示例: ```c #include <stdio.h> int main(int argc, char* argv[]) { int n1 = argc; int n2 = argc; printf("n1 * 15 = %d\n", n1 * 15); //变量乘常量 ( 常量值为非 2 的幂 ) printf("n1 * 16 = %d\n", n1 * 16); //变量乘常量 ( 常量值为 2 的幂 ) printf("2 * 2 = %d\n", 2 * 2); //两常量相乘 printf("n2 * 4 + 5 = %d\n", n2 * 4 + 5); //混合运算 printf("n1 * n2 = %d\n", n1 * n2); //两变量相乘 return 0; } ``` ```asm x86 debug vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_8= dword ptr -8 var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp sub esp, 8 mov eax, [ebp+argc] mov [ebp+var_4], eax ; n1 = argc mov ecx, [ebp+argc] mov [ebp+var_8], ecx ; n2 = argc imul edx, [ebp+var_4], 0Fh ; edx = n1 * 15 push edx push offset aN115D ; "n1 * 15 = %d\n" call sub_4010C0 add esp, 8 mov eax, [ebp+var_4] shl eax, 4 ; 左移 4 位;右移指令则是 shr push eax push offset aN116D ; "n1 * 16 = %d\n" call sub_4010C0 add esp, 8 push 4 ; 常量传播 push offset a22D ; "2 * 2 = %d\n" call sub_4010C0 add esp, 8 mov ecx, [ebp+var_8] lea edx, ds:5[ecx*4] ; 一步到位的计算 n2 * 4 +5 push edx push offset aN245D ; "n2 * 4 + 5 = %d\n" call sub_4010C0 add esp, 8 mov eax, [ebp+var_4] imul eax, [ebp+var_8] ; n1 * n2 push eax push offset aN1N2D ; "n1 * n2 = %d\n" call sub_4010C0 add esp, 8 xor eax, eax mov esp, ebp pop ebp retn _main endp ``` - [ecx*4+5] 或 [ecx*4]+5 或 5[ecx*4],这是一种寻址方式,通过这个指令只需要一条就可以计算出结果 ```asm x86 debug gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 20h call ___main mov eax, [ebp+argc] mov [esp+1Ch], eax ; n1 = argc mov eax, [ebp+argc] mov [esp+18h], eax ; n2 = argc mov edx, [esp+1Ch] mov eax, edx ; eax = edx shl eax, 4 ; eax = eax*16 sub eax, edx ; eax = eax - edx。也就是 eax = 15*edx mov [esp+4], eax mov dword ptr [esp], offset Format ; "n1 * 15 = %d\n" call _printf mov eax, [esp+1Ch] shl eax, 4 ; 左移四位 mov [esp+4], eax mov dword ptr [esp], offset aN116D ; "n1 * 16 = %d\n" call _printf mov dword ptr [esp+4], 4 mov dword ptr [esp], offset a22D ; "2 * 2 = %d\n" call _printf mov eax, [esp+18h] shl eax, 2 add eax, 5 ; 左移两位后加 5。 mov [esp+4], eax mov dword ptr [esp], offset aN245D ; "n2 * 4 + 5 = %d\n" call _printf mov eax, [esp+1Ch] imul eax, [esp+18h] mov [esp+4], eax mov dword ptr [esp], offset aN1N2D ; "n1 * n2 = %d\n" call _printf mov eax, 0 leave retn _main endp ``` ```asm x86 debug clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near var_34= dword ptr -34h var_30= dword ptr -30h var_2C= dword ptr -2Ch var_28= dword ptr -28h var_24= dword ptr -24h var_20= dword ptr -20h var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= dword ptr -10h var_C= dword ptr -0Ch var_8= dword ptr -8 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push esi sub esp, 30h mov eax, [ebp+argv] mov ecx, [ebp+argc] mov [ebp+var_8], 0 mov edx, [ebp+argc] mov [ebp+var_C], edx ; n1 = argc mov edx, [ebp+argc] mov [ebp+var_10], edx ; n2 = argc imul edx, [ebp+var_C], 0Fh ; n1 * 15 lea esi, aN115D ; "n1 * 15 = %d\n" mov [esp+34h+var_34], esi ; push esp mov [esp+34h+var_30], edx ; mov [esp+4h],edx mov [ebp+var_14], eax mov [ebp+var_18], ecx call sub_4010C0 mov ecx, [ebp+var_C] shl ecx, 4 ; 左移四位 lea edx, aN116D ; "n1 * 16 = %d\n" mov [esp+34h+var_34], edx mov [esp+34h+var_30], ecx mov [ebp+var_1C], eax call sub_4010C0 lea ecx, a22D ; "2 * 2 = %d\n" mov [esp+34h+var_34], ecx mov [esp+34h+var_30], 4 mov [ebp+var_20], eax call sub_4010C0 mov ecx, [ebp+var_10] shl ecx, 2 add ecx, 5 ; 没啥说的 lea edx, aN245D ; "n2 * 4 + 5 = %d\n" mov [esp+34h+var_34], edx mov [esp+34h+var_30], ecx mov [ebp+var_24], eax call sub_4010C0 mov ecx, [ebp+var_C] imul ecx, [ebp+var_10] lea edx, aN1N2D ; "n1 * n2 = %d\n" mov [esp+34h+var_34], edx mov [esp+34h+var_30], ecx mov [ebp+var_28], eax call sub_4010C0 xor ecx, ecx mov [ebp+var_2C], eax mov eax, ecx add esp, 30h pop esi pop ebp retn _main endp ``` - 每次 x86 clang 的参数入栈方式都是让人眼前一黑啊。 ```asm x64 debug vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_18= dword ptr -18h var_14= dword ptr -14h arg_0= dword ptr 8 arg_8= qword ptr 10h mov [rsp+arg_8], rdx mov [rsp+arg_0], ecx sub rsp, 38h mov eax, [rsp+38h+arg_0] ; n1 mov [rsp+38h+var_18], eax mov eax, [rsp+38h+arg_0] ; n2 mov [rsp+38h+var_14], eax imul eax, [rsp+38h+var_18], 0Fh mov edx, eax lea rcx, Format ; "n1 * 15 = %d\n" call printf imul eax, [rsp+38h+var_18], 10h mov edx, eax lea rcx, aN116D ; "n1 * 16 = %d\n" call printf mov edx, 4 lea rcx, a22D ; "2 * 2 = %d\n" call printf mov eax, [rsp+38h+var_14] lea eax, ds:5[rax*4] mov edx, eax lea rcx, aN245D ; "n2 * 4 + 5 = %d\n" call printf mov eax, [rsp+38h+var_18] imul eax, [rsp+38h+var_14] mov edx, eax lea rcx, aN1N2D ; "n1 * n2 = %d\n" call printf xor eax, eax add rsp, 38h retn main endp ``` - 基本能用 imul 就用了。 ```asm x64 debug gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near var_8= dword ptr -8 var_4= dword ptr -4 arg_0= dword ptr 10h arg_8= qword ptr 18h push rbp mov rbp, rsp sub rsp, 30h mov [rbp+arg_0], ecx mov [rbp+arg_8], rdx call __main mov eax, [rbp+arg_0] mov [rbp+var_4], eax ; n1 = argc mov eax, [rbp+arg_0] mov [rbp+var_8], eax ; n2 = argc mov edx, [rbp+var_4] mov eax, edx shl eax, 4 sub eax, edx mov edx, eax lea rcx, Format ; "n1 * 15 = %d\n" call printf mov eax, [rbp+var_4] shl eax, 4 mov edx, eax lea rcx, aN116D ; "n1 * 16 = %d\n" call printf mov edx, 4 lea rcx, a22D ; "2 * 2 = %d\n" call printf mov eax, [rbp+var_8] shl eax, 2 add eax, 5 mov edx, eax lea rcx, aN245D ; "n2 * 4 + 5 = %d\n" call printf mov eax, [rbp+var_4] imul eax, [rbp+var_8] mov edx, eax lea rcx, aN1N2D ; "n1 * n2 = %d\n" call printf mov eax, 0 add rsp, 30h pop rbp retn main endp ``` - 跟 x86 gcc 优化差不多 ```asm x64 debug clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near var_30= dword ptr -30h var_2C= dword ptr -2Ch var_28= dword ptr -28h var_24= dword ptr -24h var_20= dword ptr -20h var_1C= dword ptr -1Ch var_18= dword ptr -18h var_14= dword ptr -14h var_10= qword ptr -10h var_4= dword ptr -4 sub rsp, 58h mov [rsp+58h+var_4], 0 mov [rsp+58h+var_10], rdx mov [rsp+58h+var_14], ecx ; n1 = argc mov ecx, [rsp+58h+var_14] mov [rsp+58h+var_18], ecx ; n2 = argc mov ecx, [rsp+58h+var_14] mov [rsp+58h+var_1C], ecx imul edx, [rsp+58h+var_18], 0Fh lea rcx, aN115D ; "n1 * 15 = %d\n" call sub_1400010B0 mov edx, [rsp+58h+var_18] shl edx, 4 lea rcx, aN116D ; "n1 * 16 = %d\n" mov [rsp+58h+var_20], eax call sub_1400010B0 lea rcx, a22D ; "2 * 2 = %d\n" mov edx, 4 mov [rsp+58h+var_24], eax call sub_1400010B0 mov edx, [rsp+58h+var_1C] shl edx, 2 add edx, 5 lea rcx, aN245D ; "n2 * 4 + 5 = %d\n" mov [rsp+58h+var_28], eax call sub_1400010B0 mov edx, [rsp+58h+var_18] imul edx, [rsp+58h+var_1C] lea rcx, aN1N2D ; "n1 * n2 = %d\n" mov [rsp+58h+var_2C], eax call sub_1400010B0 xor edx, edx mov [rsp+58h+var_30], eax mov eax, edx add rsp, 58h retn main endp ``` - 没啥区别 - 有符号数乘以常量值,且这个常量**非2的幂**,会直接使用如下两种方法:1、有符号乘法imul指令;2、左移加减运算进行优化。 - 乘法是 2 的幂,就直接左移或者右移运算。 - **乘法运算与加法运算**的结合编译器采用 `LEA` 指令处理。LEA语句的目的并不是获取地址。 #### 除法 - **(如果看得太痛苦,直接看下面的除法总结)** - 除法指令有`有符号 idiv`和`无符号 div`。**在C++中,除法运算不保留余数**。下面将对这两个指令做一些介绍: - 共同点: 1. **操作数**:两者都是**单操作数**指令。指令中指定的操作数 (div/idiv source) 是**除数**。 2. **被除数**:被除数总是**隐含**的,并且长度是除数长度的**两倍**。它存储在特定的寄存器对中。 3. **结果**:商和余数存储在特定的寄存器中。 4. **除数限制**:除数不能为 0。如果除数为 0 或商过大导致溢出,都会触发一个中断(通常是 #DE,除法错误)。 | 除数 (source) 大小 | 被除数 | 商存储位置 | 余数存储位置 | 示例指令 | | :--: | :--: | :--: | :--: | :--: | | 8 位 (byte) | AX (16位) | AL | AH | div bl/idiv cl | | 16 位 (word) | DX:AX (32位) | AX | DX | div bx/idiv cx | | 32 位 (dword) | EDX:EAX (64位) | EAX | EDX | div ecx/idiv ebx | | 64 位 (qword) | RDX:RAX (128位) | RAX | RDX | div rcx/idiv rbx | 1. 对操作数的解释: - `div`: 将除数、被除数(`AX`, `DX:AX`, `EDX:EAX`, `RDX:RAX`)以及结果都解释为**无符号二进制数**。 - `idiv`: 将除数、被除数(`AX`, `DX:AX`, `EDX:EAX`, `RDX:RAX`)以及结果都解释为**有符号二进制数(补码)**。 2. 溢出条件: - `div`: 当商的大小超出了目标寄存器(`AL`, `AX`, `EAX`, `RAX`)所能容纳的无符号范围时,发生溢出。 - 例如:用 `div bl` (除数 8 位) 时,被除数在 `AX` (16 位无符号范围 0-65535)。如果 `AX = 0xFFFF (65535)`,除数 `bl = 0x01 (1)`,商 `AL` 应该是 65535。但 `AL` 是 8 位寄存器,最大只能表示 255 (0xFF)。65535 > 255,因此会发生溢出 (#DE)。 - `idiv`: 当商的大小超出了目标寄存器(`AL`, `AX`, `EAX`, `RAX`)所能容纳的有符号范围时,发生溢出。 - 例如:用 `idiv bl` (除数 8 位) 时,被除数在 `AX` (16 位有符号范围 -32768 到 32767)。如果 `AX = 0x8000 (-32768)`,除数 `bl = 0xFF (-1)`,商 `AL` 应该是 +32768。但 `AL` 是 8 位寄存器,有符号范围是 -128 到 127。+32768 > 127,因此会发生溢出 (#DE)。注意,虽然数学上 -32768 / -1 = +32768 是正确的,但结果超出了 8 位有符号数的表示范围。 3. 余数的**符号** (仅对 idiv 有特殊规则): - `div`: 余数总是**非负数**,并且小于除数的绝对值 (0 <= remainder < |divisor|)。 - `idiv`: 余数的符号**总是与被除数 (Dividend) 的符号相同**,并且其绝对值小于除数的绝对值 (|remainder| < |divisor|)。 - 除法的排列组合: 1. 两个无符号整数相除结果无符号。 2. 两个有符号整数相除结果有符号。 3. 有符号数和无符号数混除,结果无符号,有符号最高位作为数据处理。 - 在 C 语言和其他多数高级语言中,对整数除法规定为**向零取整**。也有人称这种取整方法为**截断除法(truncate)**。 - 编译器对除数为整型常量的除法的处理:**如果除数是变量,则只能使用除法指令。如果除数为常量,就有 了优化的余地。**后面会详细分析下各类情况的优化处理。 ##### 除数为无符号2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / 16 = %u", (unsigned)argc / 16); //变量除以常量,常量为无符号2的幂 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] shr eax, 4 ; eax=argc>>4 push eax push offset aArgc16U ; "argc / 16 = %u" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 10h call ___main mov eax, [ebp+argc] mov dword ptr [esp], offset aArgc16U ; "argc / 16 = %u" shr eax, 4 ; 右移四位 mov [esp+4], eax call _printf xor eax, eax leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] shr eax, 4 push eax push offset aArgc16U ; "argc / 16 = %u" call sub_401020 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h shr ecx, 4 mov edx, ecx lea rcx, aArgc16U ; "argc / 16 = %u" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main lea rcx, aArgc16U ; "argc / 16 = %u" shr ebx, 4 mov edx, ebx call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clangs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov edx, ecx shr edx, 4 lea rcx, aArgc16U ; "argc / 16 = %u" call sub_140001020 xor eax, eax add rsp, 28h retn main endp ``` - 对于有符号除法,C 语言的除法规则是向 0 取整(符号位不变,小数部分去掉,就是向 0 靠近),对无符号数做右移运算,编译后使用的指令为 shr,相当于向下取整。 ##### 除数为无符号非2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / 3 = %u", (unsigned)argc / 3); //变量除以常量,常量为无符号非2的幂 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, 0AAAAAAABh mul [esp+argc] ; 无符号乘法,edx.eax = argc*M shr edx, 1 ; 无符号右移一位,为什么这么算看下面介绍。注意:这里是 edx 右移一位,也就是右移 33 位。 push edx ; eax的低 32 位已经被丢弃(因为右移 33 位后,eax的所有位都被移出)。所以这里 push offset aArgc3U ; "argc / 3 = %u" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp and esp, 0FFFFFFF0h sub esp, 10h call ___main mov edx, 0AAAAAAABh ; edx = M mov dword ptr [esp], offset aArgc3U ; "argc / 3 = %u" mov eax, edx ; eax = edx mul [ebp+argc] ; edx.eax = argc*eax shr edx, 1 ; edx右移一位,也就是结果右移 33 位。 mov [esp+4], edx ; 结果入栈 call _printf xor eax, eax leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, 0AAAAAAABh mul [esp+argc] shr edx, 1 ; 和前面一样。 push edx push offset aArgc3U ; "argc / 3 = %u" call sub_401020 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, 0AAAAAAABh ; 和前面一样 mul ecx lea rcx, aArgc3U ; "argc / 3 = %u" shr edx, 1 call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main mov eax, ebx mov edx, 0AAAAAAABh ; 和前面一样 mul edx lea rcx, aArgc3U ; "argc / 3 = %u" shr edx, 1 call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, ecx mov edx, 0AAAAAAABh imul rdx, rax ; rdx = rdx * rax。 shr rdx, 21h ; 21h 就是等于十进制的 33。 lea rcx, aArgc3U ; "argc / 3 = %u" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` - 看起来很奇怪对吧,下面列一些公式来解释: 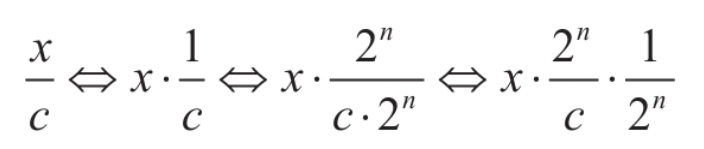 - 直接看最右边的转换结果,我们可以看到,后面的 `(2^n)/c`和 `1/(2^n)` 都是可以算出来的。把 `(2^n)/c` 当作常数 `M`,然后 `1/(2^n)` 可以当作 `右移 n 位`。也就是 `x*((2^n)/c)*(1/(2^n)) <=> X*M*(1/(2^n)) <=> (x*M)>>n` - 得到了以上的结果,我们可以在反汇编的时候通过乘的常数 `M` 和右移的位数 `n` 求出除数 `c`。 - 这里的例子中,`edx` 右移一位,也就是右移 33 位,得到 `n` 等于 33,然后 `M = (2^n)/c = 0AAAAAAABh`,其中 `n` 的结果已知,可以求出 `c` 的值约等于 3。此处的“约等于”在后面讨论除法优化原则处详细解释。 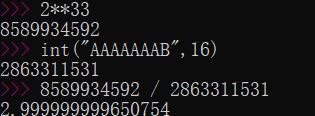 ##### 另一种除数位无符号非2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / 7 = %u", (unsigned)argc / 7); //变量除以常量,常量为无符号非2的幂 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov ecx, [esp+argc] ; ecx = argc,看不懂下面会说 mov eax, 24924925h ; eax = 24924925h = M mul ecx ; edx.eax = eax * ecx sub ecx, edx ; ecx = argc-(argc*M>>32) shr ecx, 1 ; 无符号右移,ecx=(argc-(argc*M>>32))>>1 add ecx, edx ; ecx=((argc-(argc*M>>32))>>1)+(argc*M>>32) shr ecx, 2 ; ecx=(((argc-(argc*M>>32))>>1)+(argc*M>>32))>>2 push ecx push offset aArgc7U ; "argc / 7 = %u" call sub_401040 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ebx and esp, 0FFFFFFF0h sub esp, 10h mov ebx, [ebp+argc] call ___main mov edx, 24924925h ; 同上 mov dword ptr [esp], offset aArgc7U ; "argc / 7 = %u" mov eax, ebx mul edx sub ebx, edx shr ebx, 1 add edx, ebx shr edx, 2 mov [esp+4], edx call _printf xor eax, eax mov ebx, [ebp+var_4] leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov ecx, [esp+argc] mov edx, 24924925h ; 同上 mov eax, ecx mul edx sub ecx, edx shr ecx, 1 add ecx, edx shr ecx, 2 push ecx push offset aArgc7U ; "argc / 7 = %u" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, 24924925h ; 同上 mul ecx sub ecx, edx shr ecx, 1 add edx, ecx lea rcx, aArgc7U ; "argc / 7 = %u" shr edx, 2 call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main mov eax, ebx mov edx, 24924925h ; 同上 mul edx lea rcx, aArgc7U ; "argc / 7 = %u" sub ebx, edx shr ebx, 1 add edx, ebx shr edx, 2 call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, ecx imul rdx, rax, 24924925h ; 同上 shr rdx, 20h sub ecx, edx shr ecx, 1 add edx, ecx shr edx, 2 lea rcx, aArgc7U ; "argc / 7 = %u" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` - 按照上一个例子对代码逻辑提取成数学表达式,其中设 `24924925h = M = (2^n)/c`,对汇编进行逻辑总结并简化: 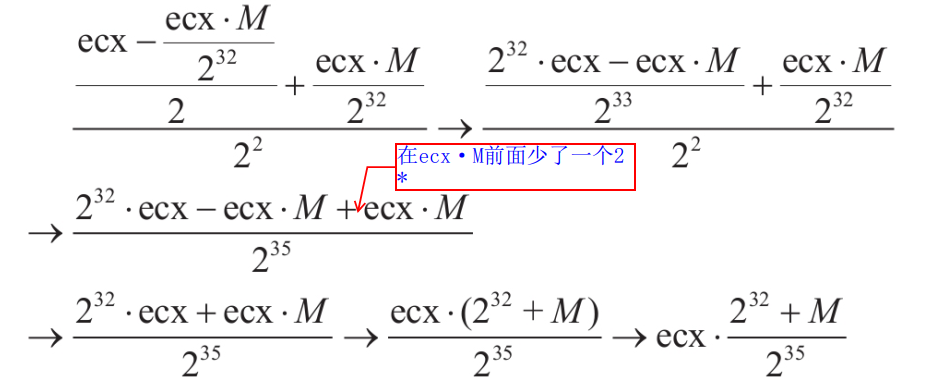 - 可以看到这里的操作是 `ecx*((2^32)+M)>>35`,这里的 `(2^32)+M` 就**相当于**是`前面一个例子中的 M`。为什么不直接使用前一个例子的方法呢? - 编译器作者在实现除法优化的过程中,通过计算得到的魔数超过了 4 字节整数范围,为了避免大数运算的开销,对此做了数学转换,于是得到最开始的表达式,规避了所有的大数计算问题。 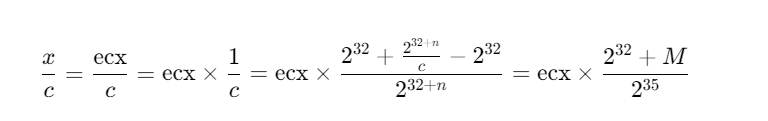 - 后续就是求解: 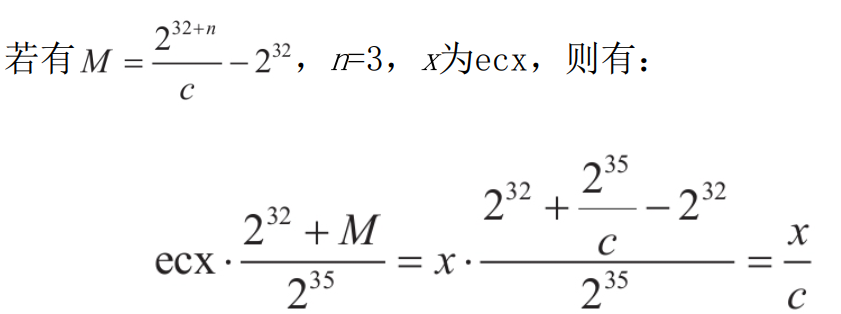 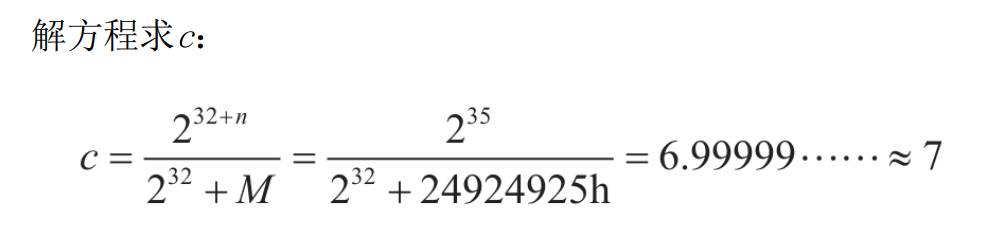 - 总结:在计算魔数后,如果值超出4字节整数的表达范围,编译器会对其进行调整。如上例中的argc/7,在计算魔数时,编译器选择$$\frac{2^{35}}{7}$$,但是其结果超出了4字节整数的表达范围,所以编译器调整魔数的取值为$$\frac{2^{35}}{7}-2^{32}$$,导致整个除法的推导也随之产生变化。也就是这里的 `M` 和前一个例子的 `M` 不一样。 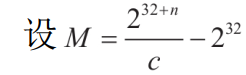 - 则: 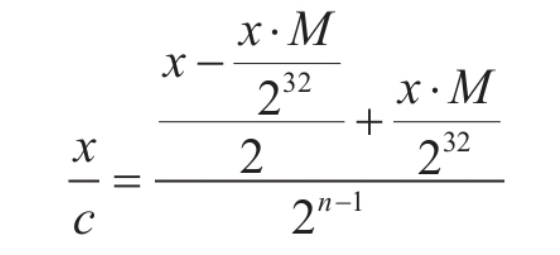 - 可得: 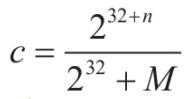 - 也就是说,当遇到: 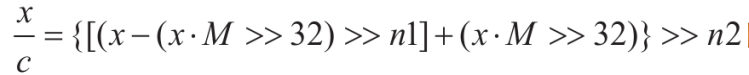 - 直接套用这个公式解决即可。其中 `n = n2 + 1`。 ##### 除数为有符号2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / 8 = %d", argc / 8); //变量除以常量,常量为 2 的 3 次方 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] cdq ; eax 符号位扩展覆盖到 edx 的每一位上,正数edx=0,负数edx=0xffffffff and edx, 7 ; 7 的二进制是 0111b,负数edx=7,正数edx=0。将 edx的值限制为 0或 7。 add eax, edx ; 直接对负数右移(sar)会导致结果偏向负无穷(例如 -9 >> 3 = -2,但期望 -9 / 8 = -1)。 ; 为了向零取整(即数学上的除法结果),需要在右移前对负数加上一个修正值。具体计算后面再说 sar eax, 3 ; 带符号右移,shr 是 无符号右移 push eax push offset aArgc8D ; "argc / 8 = %d" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ebx and esp, 0FFFFFFF0h ; 栈对齐 sub esp, 10h mov ebx, [ebp+argc] call ___main mov dword ptr [esp], offset aArgc8D ; "argc / 8 = %d" test ebx, ebx ; 按位与(AND)运算,但不保存结果,只影响标志寄存器(FLAGS),其中最高位给 SF 寄存器。 lea eax, [ebx+7] ; eax = ebx + 7。 cmovns eax, ebx ; 根据符号标志(SF)的状态决定是否执行数据移动操作。 sar eax, 3 mov [esp+4], eax call _printf xor eax, eax mov ebx, [ebp+var_4] leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] mov ecx, eax sar ecx, 1Fh ; 正数 0x00000000,负数0xffffffff,高位补符号位 shr ecx, 1Dh ; 无符号右移 29 位,正数 ecx = 0,负数 ecx = 7 add ecx, eax sar ecx, 3 push ecx push offset aArgc8D ; "argc / 8 = %d" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, ecx lea rcx, aArgc8D ; "argc / 8 = %d" cdq ; 和 x86 类似 and edx, 7 add edx, eax sar edx, 3 call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main lea edx, [rbx+7] test ebx, ebx cmovns edx, ebx ; 同 x86 gcc lea rcx, aArgc8D ; "argc / 8 = %d" sar edx, 3 call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, ecx sar eax, 1Fh ; 同 x86 clang shr eax, 1Dh lea edx, [rax+rcx] sar edx, 3 lea rcx, aArgc8D ; "argc / 8 = %d" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` - **test** 指令介绍: | 标志位 | 名称 | 说明 | |--------|------------|----------------------------------------------------------------------| | **ZF** | 零标志 | 如果 `AND` 结果为 `0`,则 `ZF = 1` | | **SF** | 符号标志 | 如果 `AND` 结果的最高位是 `1`,则 `SF = 1` | | **PF** | 奇偶标志 | 如果 `AND` 结果的低 8 位中 `1` 的个数是偶数,则 `PF = 1` | | **OF** | 溢出标志 | **总是置 0** | | **CF** | 进位标志 | **总是置 0** | - **sar**:指令介绍:保留符号右移,高位补充符号位。 - **cdq**:指令介绍:eax 符号位扩展覆盖到 edx 的每一位上,正数edx=0,负数edx=0xffffffff - 逻辑分析:  - 看清楚 x<0 时,是向上取整。由此可得下面的关系式: 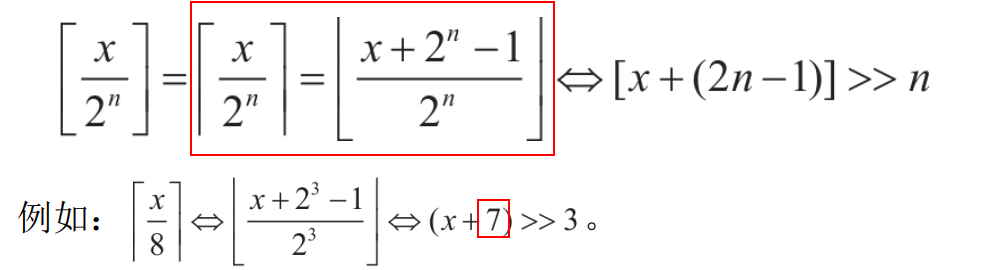 - 那为什么不能直接右移呢?很简单,在负数的情况下得到的结果不对,举个例子 -9 >> 3 = -2,但期望 -9 / 8 = -1,是错误的,只有经过上述红框的公式转换成正数以后才可以准确计算。 - 总结:当遇到数学优化公式:如果x≥0,则 $$\frac{x}{2^n} = x >> n$$,如果 x<0,则执行 $$\frac{x}{2^n} = [x+(2^n-1)] >> n$$,即可判定为优化后的除法代码,根据 n 次数可恢复除法原型。 ##### 除数为有符号非2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / 9 = %d", argc / 9); //变量除以常量,常量为非2的幂 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, 38E38E39h ; 又是这样 imul [esp+argc] ; edx.eax=argc*M sar edx, 1 ; 带符号右移 mov eax, edx shr eax, 1Fh ; 再次带符号右移 31 位,取符号位。 add eax, edx push eax push offset aArgc9D ; "argc / 9 = %d" call sub_401040 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ebx and esp, 0FFFFFFF0h sub esp, 10h mov ebx, [ebp+argc] call ___main mov edx, 38E38E39h mov dword ptr [esp], offset aArgc9D ; "argc / 9 = %d" mov eax, ebx sar ebx, 1Fh ; 只保留符号位 imul edx sar edx, 1 ; 右移 33 位 sub edx, ebx mov [esp+4], edx call _printf xor eax, eax mov ebx, [ebp+var_4] leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, 38E38E39h imul [esp+argc] mov eax, edx sar edx, 1 shr eax, 1Fh add edx, eax push edx push offset aArgc9D ; "argc / 9 = %d" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, 38E38E39h imul ecx lea rcx, aArgc9D ; "argc / 9 = %d" sar edx, 1 mov eax, edx shr eax, 1Fh add edx, eax call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main mov eax, ebx sar ebx, 1Fh mov edx, 38E38E39h imul edx lea rcx, aArgc9D ; "argc / 9 = %d" sar edx, 1 sub edx, ebx call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h movsxd rax, ecx imul rdx, rax, 38E38E39h mov rax, rdx shr rax, 3Fh sar rdx, 21h add edx, eax lea rcx, aArgc9D ; "argc / 9 = %d" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` - 这里的 `c > 0`,要分被除数 `x ≥ 0` 和 `x < 0` 的情况: - 设 `M = (2^n)/c` - x ≥ 0 时: 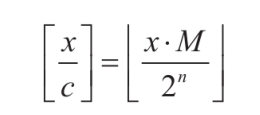 - x < 0 时:  - 当遇到数学优化公式:如果x≥0,则 $$\frac{x}{c}=x*M>>32>>n$$;如果 x<0,则 $$\frac{x}{c}=(x*M>>32>>n)+1$$ 时,基本可判定是除法优化后的代码,其除法原型为 x 除以常量 c,imul 可表明是有符号计算,其操作数是优化前的被除数 x,接下来统计右移的总次数以确定公式中的 n 值,然后使用公式 $$c=\frac{2^n}{M}$$,将魔数作为 M 值代入公式求解常量除数 c 的近似值,四舍五入取整后,即可恢复除法原型。 ##### 另一种除数为有符号非2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / 7 = %d", argc / 7); //变量除以常量,常量为非2的幂 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, 92492493h ; eax = M imul [esp+argc] ; edx.eax = argc*M add edx, [esp+argc] ; edx = (argc*M>>32) + argc sar edx, 2 ; edx=((argc*M>>32)+argc)>>2 mov eax, edx ; eax = edx shr eax, 1Fh ; eax=eax>>31取符号位 add eax, edx ; if(edx<0),eax=((argc*M>>32)+argc)>>2+1 ; if(edx >=0),eax=((argc*M>>32)+argc)>>2 push eax push offset aArgc7D ; "argc / 7 = %d" call sub_401040 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ebx and esp, 0FFFFFFF0h sub esp, 10h mov ebx, [ebp+argc] call ___main mov edx, 92492493h mov dword ptr [esp], offset aArgc7D ; "argc / 7 = %d" mov eax, ebx imul edx add edx, ebx sar ebx, 1Fh sar edx, 2 sub edx, ebx mov [esp+4], edx call _printf xor eax, eax mov ebx, [ebp+var_4] leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov ecx, [esp+argc] mov edx, 92492493h mov eax, ecx imul edx add edx, ecx mov eax, edx sar edx, 2 shr eax, 1Fh add edx, eax push edx push offset aArgc7D ; "argc / 7 = %d" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, 92492493h imul ecx add edx, ecx lea rcx, aArgc7D ; "argc / 7 = %d" sar edx, 2 mov eax, edx shr eax, 1Fh add edx, eax call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main mov eax, ebx mov edx, 92492493h imul edx lea rcx, aArgc7D ; "argc / 7 = %d" add edx, ebx sar ebx, 1Fh sar edx, 2 sub edx, ebx call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h movsxd rdx, ecx imul rax, rdx, 0FFFFFFFF92492493h shr rax, 20h add edx, eax mov eax, edx shr eax, 1Fh sar edx, 2 add edx, eax lea rcx, aArgc7D ; "argc / 7 = %d" call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` - 这里右移的次数是 32 + 2 = 34 次。 - 这里的魔数计算过程比较复杂。直接给出识别和计算除数的过程: - 优化结果: - 如果x≥0,则$$\frac{x}{c}=(x*M>>32)+x>>n$$ - 如果x<0,则$$\frac{x}{c}=\{[(x*M>>32)+x]>>n\}+1$$ - 且使用的是有符号乘法 imul,则可判定为这种优化方式。 - 除数计算公式:统计右移的总次数以确定公式中的n值,然后使用公式$$c=\frac{2^n}{M}$$,将魔数作为M值代入公式求解常量除数c的近似值 ##### 除数为有符号负2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / -4 = %d", argc / -4); //变量除以常量,常量为 -2 的 2 次方 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] cdq ; eax 符号位扩展,正数 edx=0;负数edx=0xFFFFFFFF and edx, 3 ; 负数 edx=3,正数 edx=0 add eax, edx ; 正数加 0,负数加 3。 sar eax, 2 ; 带符号右移 2 位。 neg eax push eax push offset aArgc4D ; "argc / -4 = %d" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ebx and esp, 0FFFFFFF0h sub esp, 10h mov ebx, [ebp+argc] call ___main mov dword ptr [esp], offset aArgc4D ; "argc / -4 = %d" test ebx, ebx lea eax, [ebx+3] cmovns eax, ebx sar eax, 2 neg eax mov [esp+4], eax call _printf xor eax, eax mov ebx, [ebp+var_4] leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, [esp+argc] mov ecx, eax sar ecx, 1Fh shr ecx, 1Eh add ecx, eax sar ecx, 2 neg ecx push ecx push offset aArgc4D ; "argc / -4 = %d" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, ecx lea rcx, aArgc4D ; "argc / -4 = %d" cdq and edx, 3 add edx, eax sar edx, 2 neg edx call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main lea edx, [rbx+3] test ebx, ebx cmovns edx, ebx lea rcx, aArgc4D ; "argc / -4 = %d" sar edx, 2 neg edx call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, ecx sar eax, 1Fh shr eax, 1Eh lea edx, [rax+rcx] sar edx, 2 neg edx lea rcx, aArgc4D ; "argc / -4 = %d" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` - **neg**指令:计算补码,存入原寄存器 - 优化结果: - 如果 x≥0,则$$\frac{x}{-2^n} = -(x>>n)$$ - 如果 x<0,则$$\frac{x}{-2^n} = -{[x+(2^n-1)]>>n}$$ - 则可判定为该优化方法,根据右移次数得到结果。 ##### 除数为有符号负非2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / -5 = %d", argc / -5); //变量除以常量,常量为负非2的幂 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, 99999999h ; eax=M imul [esp+argc] ; edx.eax=argc*M sar edx, 1 ; edx=argc*M>>32>>1 mov eax, edx shr eax, 1Fh ; edx=argc*M>>32>>1 add eax, edx ; edx小于零则结果加一,大于等于零则不变。 push eax push offset aArgc5D ; "argc / -5 = %d" call sub_401040 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ebx and esp, 0FFFFFFF0h sub esp, 10h mov ebx, [ebp+argc] call ___main mov edx, 66666667h mov dword ptr [esp], offset aArgc5D ; "argc / -5 = %d" mov eax, ebx sar ebx, 1Fh imul edx sar edx, 1 sub ebx, edx mov [esp+4], ebx call _printf xor eax, eax mov ebx, [ebp+var_4] leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, 99999999h imul [esp+argc] mov eax, edx sar edx, 1 shr eax, 1Fh add edx, eax push edx push offset aArgc5D ; "argc / -5 = %d" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, 99999999h imul ecx lea rcx, aArgc5D ; "argc / -5 = %d" sar edx, 1 mov eax, edx shr eax, 1Fh add edx, eax call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main mov eax, ebx sar ebx, 1Fh mov edx, 66666667h imul edx lea rcx, aArgc5D ; "argc / -5 = %d" sar edx, 1 sub ebx, edx mov edx, ebx call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h movsxd rax, ecx imul rdx, rax, 0FFFFFFFF99999999h mov rax, rdx shr rax, 3Fh sar rdx, 21h add edx, eax lea rcx, aArgc5D ; "argc / -5 = %d" call sub_140001030 xor eax, eax add rsp, 28h retn main endp ``` - M 的计算过程,当除数 c 为负数的时候:$$-M=-\frac{2^n}{|c|}=\frac{2^n}{|c|}(求补)=2^{32}-\frac{2^n}{|c|}$$,这里2^32减去这个就是求补码的过程。然后带入求解即可。 - 优化结果: - 如果 x≥0,则$$\frac{x}{c}=x*M>>32>>n$$ - 如果 x<0,则$$\frac{x}{c}=(x*M>>32>>n)+1$$ - 且使用的是有符号乘法 imul,则可判定为这种优化方式。 - 除数计算公式:由于魔数取值大于7fffffffh,而imul和sar之间未见任何调整代码,故可认定除数为负,且魔数为补码形式,接下来统计右移的总次数,以确定公式中的n值。然后使用公式$$|c|=\frac{2^n}{2^{32}-M}$$,得到结果。 ##### 另一种除数为有符号负非2的幂优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("argc / -7 = %d", argc / -7); //变量除以常量,常量为负非2的幂 return 0; } ``` ```asm x86 release vs ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov eax, 6DB6DB6Dh ; eax=M imul [esp+argc] ; edx.eax=argc*M sub edx, [esp+argc] ; edx=(argc*M>>32)-argc sar edx, 2 ; edx=(argc*M>>32)-argc>>2 mov eax, edx ; shr eax, 1Fh ; eax=edx>>31取符号位 add eax, edx ; 小于零则加一,大于等于零则加零。 push eax push offset aArgc7D ; "argc / -7 = %d" call sub_401040 add esp, 8 xor eax, eax retn _main endp ``` ```asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near var_4= dword ptr -4 argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push ebx and esp, 0FFFFFFF0h sub esp, 10h mov ebx, [ebp+argc] call ___main mov edx, 92492493h mov dword ptr [esp], offset aArgc7D ; "argc / -7 = %d" mov eax, ebx imul edx add edx, ebx sar ebx, 1Fh sar edx, 2 sub ebx, edx mov [esp+4], ebx call _printf xor eax, eax mov ebx, [ebp+var_4] leave retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch mov ecx, [esp+argc] mov edx, 6DB6DB6Dh mov eax, ecx imul edx sub edx, ecx mov eax, edx sar edx, 2 shr eax, 1Fh add edx, eax push edx push offset aArgc7D ; "argc / -7 = %d" call sub_401030 add esp, 8 xor eax, eax retn _main endp ``` ```asm x64 release vs ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h mov eax, 6DB6DB6Dh imul ecx sub edx, ecx lea rcx, aArgc7D ; "argc / -7 = %d" sar edx, 2 mov eax, edx shr eax, 1Fh add edx, eax call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rbx sub rsp, 20h mov ebx, ecx call __main mov eax, ebx mov edx, 92492493h imul edx lea rcx, aArgc7D ; "argc / -7 = %d" lea eax, [rdx+rbx] sar ebx, 1Fh sar eax, 2 mov edx, ebx sub edx, eax call printf xor eax, eax add rsp, 20h pop rbx retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near sub rsp, 28h movsxd rax, ecx imul rdx, rax, 6DB6DB6Dh shr rdx, 20h sub edx, eax mov eax, edx shr eax, 1Fh sar edx, 2 add edx, eax lea rcx, aArgc7D ; "argc / -7 = %d" call sub_140001040 xor eax, eax add rsp, 28h retn main endp ``` - 优化结果: - 如果 x≥0,则$$\frac{x}{c}=(x*M>>32)-x>>n$$ - 如果 x<0,则$$\frac{x}{c}=[(x*M>>32)-x>>n]+1$$ - 且使用的是有符号乘法 imul,则可判定为这种优化方式。 - 除数计算:由于魔数取值小于等于7fffffffh,而imul和sar之间有sub指令调整乘积,故可认定除数为负,且魔数为补码形式,接下来统计右移的总次数,以确定公式中的n值。然后使用公式$$|c|=\frac{2^n}{2^{32}-M}$$,得到结果。 #### 除法总结 1. 除数是`无符号2的幂` - 直接右移 2. 除数是`无符号非2的幂_1` - $$M =\frac{2^n}{c}$$ - 优化结果是 $$\frac{x}{c} = x*M>>32>>n$$ - 且使用的是无符号 mul 乘法指令可判定是这种优化。 - 除数计算公式 $$c=\frac{2^n}{M}$$ 3. 除数是`无符号非2的幂_2` - $$M=\frac{2^{32+n}}{c}-2^{32}$$ - 优化结果是 $$\frac{x}{c} = \{\{{[x - (x*M>>32)]>>n1\} + (x*M>>32)}\}>>n2$$ - 且使用的是无符号 mul 乘法指令即可判定是使用这种优化。**右移的优先级比加减法低,这里不用花括号框起来也可以。** - 注意 >> 算数右移会保留符号位。 - 除数计算公式:$$c = \frac{2^{32+n}}{2^{32}+M}$$ - 其中 `n = n1 + n2`,也可以直接数结果寄存器右移的总次数作为 n。 4. 除数是`有符号2的幂` - 优化结果 - 如果 x≥0,则$$\frac{x}{2^n} = x>>n$$ - 如果 x<0,则$$\frac{x}{2^n} = [x+(2^n-1)]>>n$$ - 则可判定为该优化方法,根据右移次数得到结果。 5. 除数是`有符号非2的幂_1` - $$M =\frac{2^n}{c}$$ - 优化结果: - 如果 x≥0,则$$\frac{x}{c} = x*M>>32>>n$$ - 如果 x<0,则$$\frac{x}{c} = (x*M>>32>>n)+1$$ - 且使用的是有符号乘法 imul,即可判定是使用该种优化 - 除数计算公式:统计右移的总次数以确定公式中的n值,然后使用公式$$c=\frac{2^n}{M}$$,将魔数作为M值代入公式求解常量除数c的近似值 6. 除数是`有符号非2的幂_2` - 优化结果: - 如果x≥0,则$$\frac{x}{c}=(x*M>>32)+x>>n$$ - 如果x<0,则$$\frac{x}{c}=\{[(x*M>>32)+x]>>n\}+1$$ - 且使用的是有符号乘法 imul,则可判定为这种优化方式。 - 除数计算公式:统计右移的总次数以确定公式中的n值,然后使用公式$$c=\frac{2^n}{M}$$,将魔数作为M值代入公式求解常量除数c的近似值 7. 除数是`有符号负2的幂` - 优化结果: - 如果 x≥0,则$$\frac{x}{-2^n} = -(x>>n)$$ - 如果 x<0,则$$\frac{x}{-2^n} = -{[x+(2^n-1)]>>n}$$ - 则可判定为该优化方法,根据右移次数得到结果。 8. 除数是`有符号负非2的幂_1` - 优化结果: - 如果 x≥0,则$$\frac{x}{c}=x*M>>32>>n$$ - 如果 x<0,则$$\frac{x}{c}=(x*M>>32>>n)+1$$ - 且使用的是有符号乘法 imul,则可判定为这种优化方式。 - 除数计算公式:由于魔数取值大于7fffffffh,而imul和sar之间未见任何调整代码,故可认定除数为负,且魔数为补码形式,接下来统计右移的总次数,以确定公式中的n值。然后使用公式$$|c|=\frac{2^n}{2^{32}-M}$$,得到结果。 9. 除数是`有符号负非2的幂_2` - 优化结果: - 如果 x≥0,则$$\frac{x}{c}=(x*M>>32)-x>>n$$ - 如果 x<0,则$$\frac{x}{c}=[(x*M>>32)-x>>n]+1$$ - 且使用的是有符号乘法 imul,则可判定为这种优化方式。 - 除数计算:由于魔数取值小于等于7fffffffh,而imul和sar之间有sub指令调整乘积,故可认定除数为负,且魔数为补码形式,接下来统计右移的总次数,以确定公式中的n值。然后使用公式$$|c|=\frac{2^n}{2^{32}-M}$$,得到结果。 #### 取模优化 ```c #include <stdio.h> int main(int argc, char* argv[]) { printf("%d", argc % 8); //变量模常量,常量为2的幂 printf("%d", argc % 9); //变量模常量,常量为非2的幂 return 0; } ``` ```asm x86 release vs .text:00401010 ; int __cdecl main(int argc, const char **argv, const char **envp) .text:00401010 _main proc near ; CODE XREF: __scrt_common_main_seh(void)+F5↓p .text:00401010 .text:00401010 argc = dword ptr 4 .text:00401010 argv = dword ptr 8 .text:00401010 envp = dword ptr 0Ch .text:00401010 .text:00401010 push esi .text:00401011 mov esi, [esp+4+argc] ; esi = argc .text:00401015 mov eax, esi ; eax =argc .text:00401017 and eax, 80000007h ; eax&7(最高位 1 为了检查负数)&7的目的是只保留低 3 位,因为8是2的三次方。 .text:0040101C jns short loc_401023 ; if(argc>=0) goto loc_401023 .text:0040101E dec eax ; if(argc<0) eax = ((argc&7)-1|-8)+1 书上这里有误 .text:0040101F or eax, 0FFFFFFF8h .text:00401022 inc eax .text:00401023 .text:00401023 loc_401023: ; CODE XREF: _main+C↑j .text:00401023 push eax .text:00401024 push offset unk_412160 .text:00401029 call sub_401060 .text:0040102E mov eax, 38E38E39h .text:00401033 imul esi .text:00401035 sar edx, 1 .text:00401037 mov eax, edx .text:00401039 shr eax, 1Fh .text:0040103C add eax, edx ; eax=argc/9,上面是进行了除法优化5 .text:0040103E lea eax, [eax+eax*8] ; eax=argc/9*9,这里只保留整数 .text:00401041 sub esi, eax ; esi=argc-argc/9*9,将除完的正数乘以除数,得到的数字和原来被除数的差,就是余。 .text:00401043 push esi .text:00401044 push offset unk_412160 .text:00401049 call sub_401060 .text:0040104E add esp, 10h .text:00401051 xor eax, eax .text:00401053 pop esi .text:00401054 retn .text:00401054 _main endp ``` ``` asm x86 release gcc ; int __cdecl main(int argc, const char **argv, const char **envp) public _main _main proc near argc= dword ptr 8 argv= dword ptr 0Ch envp= dword ptr 10h push ebp mov ebp, esp push esi push ebx and esp, 0FFFFFFF0h sub esp, 10h mov ebx, [ebp+argc] call ___main mov dword ptr [esp], offset aD ; "%d" mov esi, ebx sar esi, 1Fh mov edx, esi shr edx, 1Dh lea eax, [ebx+edx] and eax, 7 sub eax, edx mov [esp+4], eax call _printf mov eax, ebx mov edx, 38E38E39h mov dword ptr [esp], offset aD ; "%d" imul edx sar edx, 1 sub edx, esi lea eax, [edx+edx*8] sub ebx, eax mov [esp+4], ebx call _printf lea esp, [ebp-8] xor eax, eax pop ebx pop esi pop ebp retn _main endp ``` ```asm x86 release clang ; int __cdecl main(int argc, const char **argv, const char **envp) _main proc near argc= dword ptr 4 argv= dword ptr 8 envp= dword ptr 0Ch push esi mov esi, [esp+4+argc] mov eax, esi mov ecx, esi sar eax, 1Fh shr eax, 1Dh add eax, esi and eax, 0FFFFFFF8h sub ecx, eax push ecx push offset unk_412160 call sub_401050 add esp, 8 mov ecx, 38E38E39h mov eax, esi imul ecx mov eax, edx sar edx, 1 shr eax, 1Fh add edx, eax lea eax, [edx+edx*8] sub esi, eax push esi push offset unk_412160 call sub_401050 add esp, 8 xor eax, eax pop esi retn _main endp ``` ```asm x64 release vs .text:0000000140001010 ; int __fastcall main(int argc, const char **argv, const char **envp) .text:0000000140001010 main proc near ; CODE XREF: __scrt_common_main_seh(void)+107↓p .text:0000000140001010 ; DATA XREF: .pdata:ExceptionDir↓o .text:0000000140001010 push rbx .text:0000000140001012 sub rsp, 20h .text:0000000140001016 mov edx, ecx .text:0000000140001018 mov ebx, ecx .text:000000014000101A and edx, 80000007h .text:0000000140001020 jge short loc_140001029 .text:0000000140001022 dec edx .text:0000000140001024 or edx, 0FFFFFFF8h .text:0000000140001027 inc edx .text:0000000140001029 .text:0000000140001029 loc_140001029: ; CODE XREF: main+10↑j .text:0000000140001029 lea rcx, unk_1400122C0 .text:0000000140001030 call sub_140001060 .text:0000000140001035 mov eax, 38E38E39h .text:000000014000103A lea rcx, unk_1400122C0 .text:0000000140001041 imul ebx .text:0000000140001043 sar edx, 1 .text:0000000140001045 mov eax, edx .text:0000000140001047 shr eax, 1Fh .text:000000014000104A add edx, eax .text:000000014000104C lea eax, [rdx+rdx*8] .text:000000014000104F sub ebx, eax .text:0000000140001051 mov edx, ebx .text:0000000140001053 call sub_140001060 .text:0000000140001058 xor eax, eax .text:000000014000105A add rsp, 20h .text:000000014000105E pop rbx .text:000000014000105F retn .text:000000014000105F main endp ``` ```asm x64 release gcc ; int __fastcall main(int argc, const char **argv, const char **envp) public main main proc near push rsi push rbx sub rsp, 28h mov ebx, ecx call __main lea rcx, aD ; "%d" mov esi, ebx sar esi, 1Fh mov eax, esi shr eax, 1Dh lea edx, [rbx+rax] and edx, 7 sub edx, eax call printf mov eax, ebx mov ecx, 38E38E39h imul ecx lea rcx, aD ; "%d" mov eax, edx sar eax, 1 sub eax, esi lea eax, [rax+rax*8] sub ebx, eax mov edx, ebx call printf xor eax, eax add rsp, 28h pop rbx pop rsi retn main endp ``` ```asm x64 release clang ; int __fastcall main(int argc, const char **argv, const char **envp) main proc near push rsi push rdi sub rsp, 28h mov esi, ecx mov eax, ecx sar eax, 1Fh shr eax, 1Dh add eax, ecx and eax, 0FFFFFFF8h mov edx, ecx sub edx, eax lea rdi, unk_1400122C0 mov rcx, rdi call sub_140001060 movsxd rdx, esi imul rax, rdx, 38E38E39h mov rcx, rax shr rcx, 3Fh sar rax, 21h add eax, ecx lea eax, [rax+rax*8] sub edx, eax mov rcx, rdi call sub_140001060 xor eax, eax add rsp, 28h pop rdi pop rsi retn main endp ``` ### 算术结果溢出 ### 自增和自减 ## 关系运算和逻辑运算 ### 关系运算和条件跳转的对应 ### 表达式短路 ### 条件表达式 ## 跳转指令 ## 位运算 ## 编译器使用的优化技巧 ### 流水线优化规则 ### 分支优化规则 ### 高速缓存优化规则 ## 一次算法逆向之旅 ## 总结
别卷了
2025年9月16日 10:54
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码